
ここ数年、専門家でなくてもプログラミングをする人が増えてきました。
プログラミングができれば定型的な作業を自動化でき、仕事を効率化できます。
この記事では、プログラミング言語「Python(パイソン)」で自動化できる7つのことを紹介します。
すべてサンプルコードがあります。
ぜひコピー・ペーストして使ってください。
1. WEBデータの収集
WEBからの情報収集はビジネスマンの基本スキルです。
Pythonを使えばWEBの情報収集を自動化もできます。
Pythonのライブラリである「requests」と「BeautifulSoup」を使ったWEBの情報収集の自動化のやり方を紹介します。
最終的なサンプルコードは以下の通りです。
import requests
from bs4 import BeautifulSoup
import csv
# データを取得したいサイトのURL
url = 'https://www.example.com/'
# requestsモジュールを使用してHTMLを取得する
response = requests.get(url)
# BeautifulSoup4を使用してHTMLを解析する
soup = BeautifulSoup(response.content, 'html.parser')
# WEBサイトのタイトルを取得する
title = soup.title.text
# WEBサイトに含まれるすべての画像のリンクを取得する
images = []
for image in soup.find_all('img'):
src = image.get('src')
if src:
images.append(src)
# 結果を出力する
print("タイトル:", title)
print("画像パス:", images)
# CSVに結果を保存する
with open('data.csv', mode='w') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(['タイトル', '画像パス'])
for img_path in images:
writer.writerow([title, img_path])1.1. Pythonを使ってWEBサイトのデータを取得する
Pythonを使ってWEBサイトのデータを収集するにはrequestsモジュールを使います。
使い方は簡単です。
import requests
# データを取得したいサイトのURL
url = 'https://www.example.com/'
# requestsモジュールを使用してHTMLを取得する
response = requests.get(url)import requestsと記述してrequestsモジュールを読み込みます。
それからデータを取得したいサイトのURLを requests.get の引数に入れるだけです。
これを実行すると変数responseにWEBサイトのデータが代入されます。
ここでは https://www.example.com/ のデータを取得しています。
<Response [200]>1.2. 取得したデータを解析して必要な情報を取り出す
取得したWEBのデータはResponseという型のオブジェクトにまとめられています。
ここからデータを取り出します。
データは response.content という変数に入っています。
b'<!doctype html>\n<html>\n<head>\n <title>Example Domain</title>\n\n <meta charset="utf-8" />\n <meta http-equiv="Content-type" content="text/html; charset=utf-8" />\n <meta name="viewport" content="width=device-width, initial-scale=1" />\n <style type="text/css">\n body {\n background-color: #f0f0f2;\n margin: 0;\n padding: 0;\n font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;\n \n }\n div {\n width: 600px;\n margin: 5em auto;\n padding: 2em;\n background-color: #fdfdff;\n border-radius: 0.5em;\n box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);\n }\n a:link, a:visited {\n color: #38488f;\n text-decoration: none;\n }\n @media (max-width: 700px) {\n div {\n margin: 0 auto;\n width: auto;\n }\n }\n </style> \n</head>\n\n<body>\n<div>\n <h1>Example Domain</h1>\n <p>This domain is for use in illustrative examples in documents. You may use this\n domain in literature without prior coordination or asking for permission.</p>\n <p><a href="https://www.iana.org/domains/example">More information...</a></p>\n</div>\n</body>\n</html>\n'データの中身はHTMLです。
このままでは人間には扱いにくいです。
そこでHTMLデータを解析して必要な情報だけを取り出します。
HTMLデータの解析と情報の抽出にはBeautifulSoupモジュールを使います。
以下のコマンドをコマンドプロンプトやターミナルで実行してBeautifulSoup(ビューティフル・スープ)をインストールします。
pip install BeautifulSoup4BeautifulSoupを使うと、以下のようにしてHTMLを解析し、必要なデータを取り出せます。
ここではWEBサイトのタイトルを抽出しています。
import requests
from bs4 import BeautifulSoup
url = 'https://www.example.com/'
response = requests.get(url)
# BeautifulSoup4を使用してHTMLを解析する
soup = BeautifulSoup(response.content, 'html.parser')
# WEBサイトのタイトルを取得する
title = soup.title.text
print("タイトル:", title) # Example Domain続いてWEBサイトに含まれる「画像」のURLを取り出してみましょう。
# WEBサイトに含まれるすべての画像のリンクを取得する
images = []
for image in soup.find_all('img'):
src = image.get('src')
if src:
images.append(src)
# 結果を出力する
print("画像パス:", images)例として利用しているExample Domainのページには画像が含まれていません。そのため、他のサイトのURLで試してみましょう。
当サイトのトップページを指定して実行すると以下のように画像のURLのリストを取得できます。
画像パス: ['https://chmod774.com/wp-content/uploads/2023/03/PAK85_coding15095904_TP_V-320x180.jpg', 'https://chmod774.com/wp-content/uploads/2023/04/sorasanPAR5540_TP_V-320x180.jpg', 'https://chmod774.com/wp-content/uploads/2023/04/sorasanPAR55376_TP_V-320x180.jpg', 'https://chmod774.com/wp-content/uploads/2023/02/sorasanPAR55476_TP_V-320x180.jpg', 'https://chmod774.com/wp-content/uploads/2023/03/sorasanPAR55366_TP_V-320x180.jpg', 'https://chmod774.com/wp-content/uploads/2023/02/sorasanPAR55380_TP_V-320x180.jpg', 'https://chmod774.com/wp-content/uploads/2023/03/harinezumiIMGL8714_TP_V-320x180.jpg', 'https://chmod774.com/wp-content/uploads/2023/03/iphoneFTHG1293_TP_V-320x180.jpg', 'https://chmod774.com/wp-content/uploads/2023/03/kinemaPAR514972340_TP_V-320x180.jpg', 'https://chmod774.com/wp-content/uploads/2023/03/haro20220227-A7401954_TP_V-320x180.jpg']タイトルや画像URLの他にもHTMLタグを指定してデータを取り出せます。
soup.p # pタグだけを取り出す
soup.find_all('a') # すべてのaタグを取り出す
soup.find(id="link3") # idが"link3"の要素を取り出す詳しくはBeautifulSoupの公式ドキュメントを参照してください。
1.3. 取り出したデータを保存する
最後に、取り出した情報をcsvファイルに保存します。
csvファイルの読み書きにはcsvモジュールを使います。
import csv
# CSVに結果を保存する
with open('data.csv', mode='w') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(['タイトル', '画像パス'])
for img_path in images:
writer.writerow([title, img_path])このようにWEBデータを取得して解析し、必要なデータをcsvに保存できます。
2. 表形式のデータの読み書き
Excelやcsvなどの表形式データの取り扱いも、現代のビジネスには欠かせないスキルです。
しかし、Excelを皆と同じように使っても作業効率は上がりません。
Pythonを使えば表形式データ整理を格段に効率化できます。
例として、WEBから収集したデータをcsvのシートに書き込み、csvファイルの「画像へのリンク」を「ファイル名」に変換して、別のcsvに保存する例を紹介します。
ここでは、WEBデータは既に取得してあり、以下のようにPythonのリストになっているものとします。
data = [
("chmod","https://chmod774.com/wp-content/uploads/2023/03/PAK85_coding15095904_TP_V-320x180.jpg"),
("chmod","https://chmod774.com/wp-content/uploads/2023/04/sorasanPAR5540_TP_V-320x180.jpg"),
("chmod","https://chmod774.com/wp-content/uploads/2023/04/sorasanPAR55376_TP_V-320x180.jpg"),
("chmod","https://chmod774.com/wp-content/uploads/2023/02/sorasanPAR55476_TP_V-320x180.jpg"),
("chmod","https://chmod774.com/wp-content/uploads/2023/03/sorasanPAR55366_TP_V-320x180.jpg"),
("chmod","https://chmod774.com/wp-content/uploads/2023/02/sorasanPAR55380_TP_V-320x180.jpg"),
("chmod","https://chmod774.com/wp-content/uploads/2023/03/harinezumiIMGL8714_TP_V-320x180.jpg"),
("chmod","https://chmod774.com/wp-content/uploads/2023/03/iphoneFTHG1293_TP_V-320x180.jpg"),
("chmod","https://chmod774.com/wp-content/uploads/2023/03/kinemaPAR514972340_TP_V-320x180.jpg"),
("chmod","https://chmod774.com/wp-content/uploads/2023/03/haro20220227-A7401954_TP_V-320x180.jpg"),
]サンプルコードの完成形は以下です。
import csv
import os
# リストをcsvファイルに保存する
with open('data.csv', mode='w') as csv_file:
writer = csv.writer(csv_file)
writer.writerows(data)
# 保存したcsvファイルを読み込む
with open('data.csv', mode='r') as csv_file:
reader = csv.reader(csv_file)
with open('new_data.csv', mode='w') as new_csv_file:
writer = csv.writer(new_csv_file)
for row in reader:
# 2列目のリンクからファイル名だけを取り出す
base_name = os.path.basename(row[1])
row[1] = base_name
# 別のCSVファイルに保存する
writer.writerow(row)2.1. データをcsvファイルに書き込む
まずはdata(リスト形式のデータ)をcsvファイルに書き込みます。
import csv
# リストをcsvファイルに保存する
with open('data.csv', mode='w') as csv_file:
writer = csv.writer(csv_file)
writer.writerows(data)書き込みは csv.writer の writerows メソッドを呼び出すだけです。
2.2. csvファイルを読み込む
続いて、保存したcsvファイルを読み込みます。
open('ファイル名', mode='r')とするとファイルを読み込みモードで開きます。
「mode=’w’」が「書き込みモード」、「mode=’r’」が「読み込みモード」です。
# 保存したcsvファイルを読み込む
with open('data.csv', mode='r') as csv_file:
reader = csv.reader(csv_file)2.3. ファイルの中身を編集して新しいファイルに書き込む
最後に、csvファイルの2列目にある「リンク(URL)」を「ファイル名」に置き換えます。
そして、置き換え後のデータを新しいcsvファイルに保存します。
リンクからファイル名を取り出すにはosモジュールを使用します。
os.path.basename('リンクテキスト') でリンクからファイル名を抽出できます。
import os
# 保存したcsvファイルを読み込む
with open('data.csv', mode='r') as csv_file:
reader = csv.reader(csv_file)
# 別のcsvファイルに保存する
with open('new_data.csv', mode='w') as new_csv_file:
writer = csv.writer(new_csv_file)
for row in reader:
# 2列目のリンクからファイル名だけを取り出す
base_name = os.path.basename(row[1])
row[1] = base_name
# 別のcsvファイルにデータを書き込み
writer.writerow(row)new_data.csvという名前のファイルが作成されて、以下のように書き込まれていたらOKです。
chmod,PAK85_coding15095904_TP_V-320x180.jpg
chmod,sorasanPAR5540_TP_V-320x180.jpg
chmod,sorasanPAR55376_TP_V-320x180.jpg
chmod,sorasanPAR55476_TP_V-320x180.jpg
chmod,sorasanPAR55366_TP_V-320x180.jpg
chmod,sorasanPAR55380_TP_V-320x180.jpg
chmod,harinezumiIMGL8714_TP_V-320x180.jpg
chmod,iphoneFTHG1293_TP_V-320x180.jpg
chmod,kinemaPAR514972340_TP_V-320x180.jpg
chmod,haro20220227-A7401954_TP_V-320x180.jpg3. ファイル操作の自動化
パソコンを使って仕事をしていると、スライドやドキュメントなど、様々なファイルが増えてくると思います。
Pythonを使えばたくさんのファイルを一括で操作できます。
例として、特定の文字列をファイル名に含むファイルをひとつのフォルダにまとめる方法を紹介します。
コードの完成形は以下です。
import os
import shutil
# 移動先のフォルダ名
target_folder = "target"
# 検索するディレクトリ
search_directory = "directory"
# 検索する文字列
search_string = "target_string"
# 検索ディレクトリ内のファイルをすべて検索
for root, dirs, files in os.walk(search_directory):
for file in files:
# ファイル名に指定した文字列が含まれる場合
if search_string in file:
# 移動先フォルダが存在しない場合は、作成する
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# ファイルを移動する
shutil.move(os.path.join(root, file), os.path.join(target_folder, file))3.1. フォルダに含まれるすべてのファイルを探索する
まずは検索対象のフォルダに含まれるすべてのファイルを探索します。
osモジュールのos.walkを使って以下のように書きます。
import os
# 検索するディレクトリ
search_directory = "directory"
# 検索する文字列
search_string = "target_string"
# 検索ディレクトリ内のファイルをすべて検索
for root, dirs, files in os.walk(search_directory):
print(f"root {root}")
print(f"dirs {dirs}")
print(f"files {files}")os.walkは引数で指定されたフォルダを起点に、ファイルとフォルダを探索して3つの戻り値を返します。探索中に、他のフォルダを見つけた場合は、そのフォルダに潜ってさらに探索をします。
os.walkの1つ目の戻り値(変数root)には、検索中のフォルダのパスが入ります。
2つ目の戻り値(変数dirs)には、検索中のフォルダに含まれているフォルダのリストが入ります。
3つ目の戻り値(変数files)には、検索中のフォルダに含まれているファイルのリストが入ります。
3つ目の戻り値から、ファイルのリストが得られます。
3.2. ファイル名に特定の文字列を含むかを判定する
次に、ファイル名に特定の文字列を含むかを判定します。
特定の文字列を含むかどうか判定するにはPythonのin演算子を使用します。
in演算子は次のように文字列が含まれていればTrue、含まれていなければFalseと判定します。
print("abc" in "abcdefg") # True
print("abc" in "defghij") # Falseこれを使ってファイル名に特定の文字列が含まれるかを判定します。
import os
# 検索するディレクトリ
search_directory = "directory"
# 検索する文字列
search_string = "target_string"
# 検索ディレクトリ内のファイルをすべて検索
for root, dirs, files in os.walk(search_directory):
for file in files:
# ファイル名に指定した文字列が含まれるか判定する
if search_string in file:
print(f"ファイル {file} には {search_string} が含まれます")3.3. 見つかったファイルを一括して移動する
ファイル名に指定の文字列が含まれていた場合、そのファイルを別のフォルダに移動します。
ファイルを他のフォルダに移動するにはshutilモジュールのshutil.moveを使用します。
shutil.move("移動元のファイルのパス", "移動先のディレクトリのファイルのパス")該当するファイルを指定したフォルダ(target_folder)に移動します。
移動先のフォルダが存在しない場合は新たに作成します。
import os
import shutil
# 移動先のフォルダ名
target_folder = "target"
# 検索するディレクトリ
search_directory = "directory"
# 検索する文字列
search_string = "target_string"
# 検索ディレクトリ内のファイルをすべて検索
for root, dirs, files in os.walk(search_directory):
for file in files:
# ファイル名に指定した文字列が含まれる場合
if search_string in file:
# 移動先フォルダが存在しない場合は、作成する
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# ファイルを移動する
shutil.move(os.path.join(root, file), os.path.join(target_folder, file))4. 画像編集
- 画像を一括でトリミングしたい
- 人物の顔にモザイクをかけたい
- 複数の写真の中から笑顔の写真だけを抽出したい
こんなときにもPythonが役に立ちます。
PythonのOpenCV(オープン・シー・ヴィ)という画像処理ライブラリを使用すると、プログラムから画像を編集できます。
OpenCVを使うと画像のトリミングやリサイズのような簡単な編集だけでなく「人物の顔認識」や「笑顔の検出」「輪郭線の抽出」「モザイク」や「ぼかし処理」など様々な画像処理ができます。
例として、複数枚の人物の画像から顔を検出して、その部分にモザイクをかけるコードを書いてみましょう。
コードの完成形は以下になります。
import cv2
import glob
# 顔検出器を読み込む
# https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 画像が保存されているフォルダ内の全画像を読み込む
for filename in glob.glob('images/*.jpg'):
# 画像を読み込む
img = cv2.imread(filename)
# 画像をグレースケールに変換する
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 顔を検出する
faces = face_cascade.detectMultiScale(
gray,
scaleFactor=1.1, # 1.01に設定するとより検出率が高まりますが誤検出も増えます
minNeighbors=2,
minSize=(1, 1)
)
# 顔部分にモザイクをかける
for (x, y, w, h) in faces:
cv2.rectangle(img, (x,y),(x+w, y+h), (0,0,255), thickness=2)
# 顔部分を切り取る
face = img[y:y+h, x:x+w]
# 顔部分をリサイズする
face = cv2.resize(face, (int(w/10), int(h/10)))
# モザイクをかける
face = cv2.resize(face, (w, h), interpolation=cv2.INTER_NEAREST)
# モザイクをかけた顔部分を元の画像に貼り付ける
img[y:y+h, x:x+w] = face
# モザイクをかけた画像を表示する
cv2.imshow('Mosaic Image', img)
cv2.waitKey(0)
# モザイクをかけた画像を保存する
cv2.imwrite('mosaic_' + filename, img)
# ウィンドウを閉じる
cv2.destroyAllWindows()4.1. 画像を読み込む
まずは画像を読み込みます。
globモジュールを使ってフォルダ内の画像ファイルを検索し、OpenCVのimreadを使って読み込みます。
import cv2
import glob
# 画像が保存されているフォルダ内の全画像を読み込む
for filename in glob.glob('images/*.jpg'):
# 画像を読み込む
img = cv2.imread(filename)import cv2 でOpenCVのモジュールを読み込めます。
cv2.imreag('ファイル名') とすることでOpenCVで画像ファイルを読み込めます。
また、今回はimagesフォルダに含まれるjpg画像をすべて処理したいので glob.glob('images/*.jpg') としてjpgファイルを検索します。ここで抽出されたファイルパスに対して繰り返し処理をします。
globモジュールはパスをパターン解析できるモジュールです。
glob.glob("検索するフォルダのパス/*.[拡張子]") とすれば、該当する拡張子を持つファイルをフォルダから見つけてくれます。
4.2. 画像をグレースケールに変換する
今回は、画像中の人物の顔を検出してモザイクをかけます。
モザイクをかける処理の全体の流れは以下になります。
- 画像をグレースケール画像(白黒画像)に変換する(cv2.cvtColor)
- 顔を検出する(cv2.CascadeClassifierとcascade.detectMultiScale)
- 検出した部分にモザイク処理を適用する
ここではまず画像をグレースケールに変換します。
グレースケールに変換することで、画像のデータ量を削減し、検出時間を削減できます。
グレースケール画像への変換は以下の通りです。
import cv2
import glob
# 画像が保存されているフォルダ内の全画像を読み込む
for filename in glob.glob('images/*.jpg'):
# 画像を読み込む
img = cv2.imread(filename)
# 画像をグレースケールに変換する
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)cv2.cvtColor('imreadで読み込んだ画像', cv2.COLOR_BGR2GRAY) と書くだけで、画像をグレースケールに変換できます。
cv2.cvtColorは画像の色空間を変換するための関数です。
第一引数に画像データ(numpy.ndarray)を与えて、第二引数に変換先の色空間の変換コードを指定します。
cv2.COLOR_BGR2GRAYは「BGRからグレースケールへの変換」を示す変換コードです。
これで、読み込んだカラー画像をグレースケールに変換できます。
4.3. 顔を検出する
続いて、グレースケール画像から顔を検出します。
OpenCVで人物の顔を検出し、顔がある場所を示す座標値(x, y)を取得します。
人物の顔を検出するには、顔を検出するための「検出器」が必要です。
OpenCVのGitHubのリポジトリからxmlファイルをダウンロードしておきましょう。
これを以下のコードと同じフォルダに入れておきます。
そのうえで以下を実行すると人物の顔を検出して、検出した部分を長方形で囲むことができます。
import cv2
import glob
# 顔検出器を読み込む
# https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 画像が保存されているフォルダ内の全画像を読み込む
for filename in glob.glob('images/*.jpg'):
# 画像を読み込む
img = cv2.imread(filename)
# 画像をグレースケールに変換する
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 顔を検出する
faces = face_cascade.detectMultiScale(
gray,
scaleFactor=1.1, # 1.01に設定するとより検出率が高まりますが誤検出も増えます
minNeighbors=2,
minSize=(1, 1)
)
# 検出した顔を長方形で囲む
for (x, y, w, h) in faces:
cv2.rectangle(img, (x,y),(x+w, y+h), (0,0,255), thickness=2)cv2.CascadeClassifierは、画像中の物体を検出するためのクラスです。
このクラスに分類器のファイル(xml)を渡して初期化することで分類器を作成します。
今回はhaarcascade_frontalface_default.xmlという顔検出のファイルを渡しているので、人物の顔を検出する分類器(検出器)が作られます。
読み込んだ検出器を変数face_cascadeに入れます。
その後、face_cascade.detectMultiScale関数にグレースケール画像を渡して呼び出すことで、顔を検出します。
faces = face_cascade.detectMultiScale(
gray, # グレースケール画像を渡す
scaleFactor=1.1, # 1.01に設定するとより検出率が高まりますが誤検出も増えます
minNeighbors=2,
minSize=(1, 1)
)※detectMultiScaleの引数の詳細はOpenCVの公式ドキュメントを参照してください。
顔が検出できると、変数facesに顔の座標が渡されます。
顔は複数検出される場合があります。
そのため、以下のようにfor文で繰り返し処理します。
for (x, y, w, h) in faces:
cv2.rectangle(img, (x,y),(x+w, y+h), (0,0,255), thickness=2)facesのひとつの要素は、4つのデータを含む配列(ndarray)になっています。
- x: 検出された顔の左上の点のx座標
- y: 検出された顔の左上の点のy座標
- w: 検出された顔の横幅(width)
- h: 検出された顔の縦幅(height)
これらのデータを使って検出された顔を長方形で囲みます。
長方形で囲むにはcv2.rectangleを使用します。
cv2.rectangle(
img, # 画像データ
(x, y), # (長方形の左上のx座標, 長方形の左上のy座標)
(x + w, y + h), # (長方形の右下のx座標, 長方形の右下のy座標)
(0, 0, 255), # 色(GBR)
thickness=2 # 線の太さ
)このようにして顔を検出して、検出した場所を長方形で囲むことができます。
4.4. 検出した顔にモザイクをかける
最後に、検出した顔の位置にモザイク処理をして表示します。
モザイク処理は、
- 顔部分を切り取る
- 切り取った顔画像を1/10サイズに縮小する
- 縮小した顔画像をもとのサイズに戻す(その際にない情報を周囲のデータで埋める)
という流れになります。
画像は圧縮して小さくすると一部の情報が失われます。
画像を復元するときに、失われた情報を適当に埋めることでモザイク画像ができます。
for (x, y, w, h) in faces:
cv2.rectangle(img, (x,y),(x+w, y+h), (0,0,255), thickness=2)
# 顔部分を切り取る
face = img[y:y+h, x:x+w]
# 顔画像を縮小する
face = cv2.resize(face, (int(w/10), int(h/10)))
# 縮小した顔画像をもとのサイズに戻す(このとき近くのピクセルのデータで足りない部分を埋める→モザイク)
face = cv2.resize(face, (w, h), interpolation=cv2.INTER_NEAREST)
# モザイクをかけた顔部分を元の画像に貼り付ける
img[y:y+h, x:x+w] = faceモザイクをかけた後で、モザイク適用済みの画像を表示・保存します。
完成形が以下です。
import cv2
import glob
# 顔検出器を読み込む
# https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 画像が保存されているフォルダ内の全画像を読み込む
for filename in glob.glob('images/*.jpg'):
# 画像を読み込む
img = cv2.imread(filename)
# 画像をグレースケールに変換する
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 顔を検出する
faces = face_cascade.detectMultiScale(
gray,
scaleFactor=1.1, # 1.01に設定するとより検出率が高まりますが誤検出も増えます
minNeighbors=2,
minSize=(1, 1)
)
# 顔部分にモザイクをかける
for (x, y, w, h) in faces:
cv2.rectangle(img, (x,y),(x+w, y+h), (0,0,255), thickness=2)
# 顔部分を切り取る
face = img[y:y+h, x:x+w]
# 顔部分をリサイズする
face = cv2.resize(face, (int(w/10), int(h/10)))
# 画像をもとのサイズに戻す(このとき近くのピクセルのデータで足りない部分を埋める)
face = cv2.resize(face, (w, h), interpolation=cv2.INTER_NEAREST)
# モザイクをかけた顔部分を元の画像に貼り付ける
img[y:y+h, x:x+w] = face
# モザイクをかけた画像を表示する
cv2.imshow('Mosaic Image', img)
cv2.waitKey(0)
# モザイクをかけた画像を保存する
cv2.imwrite('mosaic_' + filename, img)
# ウィンドウを閉じる
cv2.destroyAllWindows()5. PDFからのテキスト抽出
ビジネスではPDFを使って資料共有することが多いと思います。
PDFは共有してもレイアウトが崩れないという利点がありますが、テキストや画像を抜き出すことが面倒であるというデメリットもあります。
しかし、Pythonを使えば複数のPDFファイルから一括してテキストを抜き出すことができます。
PDFに含まれるテキストを機械的に処理したいときに便利です。
PDFファイルを扱うにはPDFMinerというライブラリを使うのが一般的です。
ここではPDFMinerを使ってPDFファイルからテキストを抽出するコードを書いてみましょう。
コードの完成形は以下です。
import io
import pdfminer
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfpage import PDFPage
pdf_path = "example.pdf"
resource_manager = PDFResourceManager()
text_content = io.StringIO()
laparams = pdfminer.layout.LAParams()
device = TextConverter(resource_manager, text_content, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
with open(pdf_path, 'rb') as file:
for page in PDFPage.get_pages(file, check_extractable=True):
interpreter.process_page(page)
text = text_content.getvalue()
device.close()
text_content.close()
# PDFファイルからテキストを抽出する
print(text)なお、今回のコードで使用するサンプルとしてPDFファイル(example.pdf)を用意しました。
手元にPDFがない方は以下をダウンロードして使ってください。
5.1. PDFMinerのインストール
はじめにPDFMinerをインストールします。
PDFMinerはターミナルやコマンドプロンプトで以下のpipコマンドを実行することでインストールできます。
pip install pdfminer.six5.2. PDFMinerのセットアップ
次にPDFMinerをセットアップします。
やや込み入っていますが以下のようにしてテキスト抽出用にセットアップできます。
import io
import pdfminer
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfpage import PDFPage
resource_manager = PDFResourceManager()
text_content = io.StringIO()
laparams = pdfminer.layout.LAParams()
device = TextConverter(resource_manager, text_content, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)5.3. PDFを読み込んでテキストを抽出する
PDFMinerでPDFからテキストを取り出すには以下のようにします。
with open("example.pdf", 'rb') as file:
for page in PDFPage.get_pages(file, check_extractable=True):
interpreter.process_page(page)
text = text_content.getvalue() # 取り出したテキストが入る
device.close()
text_content.close()
print(text) # テキストを出力するPDFからテキストを取り出した後に device(TextConverter)と text_content(io.StringIO())はcloseしておきます。
抽出したテキストは変数textに代入されます。
以下のように出力され、textが抽出できていることがわかります。
This is example text. This is example text. This is example text. This is example text. This
is example text. This is example text. This is example text. ...(略)6. 画面操作の自動化
WEBサイトやソフトウェアの都合で、手作業で同じ操作を繰り返さなければならないことがあると思います。
こういった場合もPythonで操作を効率化できます。
PythonではPyAutoGUIというライブラリを使ってマウスやキーボードの操作を自動化できます。
画面上にある特定の画像を探し出してクリックしたり、文字を入力することも可能です。
ここではPyAutoGUIを使ってフォームの入力と送信を自動化するコードを書いてみましょう。
完成形のコードは以下です。
import pyautogui
import pyperclip
# フォームに入力するテキスト
name = "山田 太郎"
email = "yamada@example.com"
# 「お名前」のテキストボックスの画像を検索してクリックさせる
x, y = pyautogui.locateCenterOnScreen("name_input.png")
# テキストボックスに名前を入力する
pyautogui.doubleClick(x / 2, y / 2) # テキストボックスをダブルクリック
pyperclip.copy(name) # 日本語を入力するためクリップボードに変数の値をコピーする
pyautogui.hotkey('command', 'v') # Windowsの場合は pyautogui.hotkey('ctrl', 'v')
# 「メールアドレス」のテキストボックスの画像を検索してクリックさせる
x, y = pyautogui.locateCenterOnScreen("email_input.png")
# テキストボックスにメールアドレスを入力する
pyautogui.doubleClick(x / 2, y / 2) # テキストボックスをダブルクリック
pyperclip.copy(email)
pyautogui.hotkey('command', 'v') # Windowsの場合は pyautogui.hotkey('ctrl', 'v')
# 送信ボタンをクリックする
x, y = pyautogui.locateCenterOnScreen("submit.png")
pyautogui.click(x / 2, y / 2) # 送信ボタンの座標なお、操作する対象はWEBのフォームです。
今回は以下のお問い合わせフォームを作成しました。
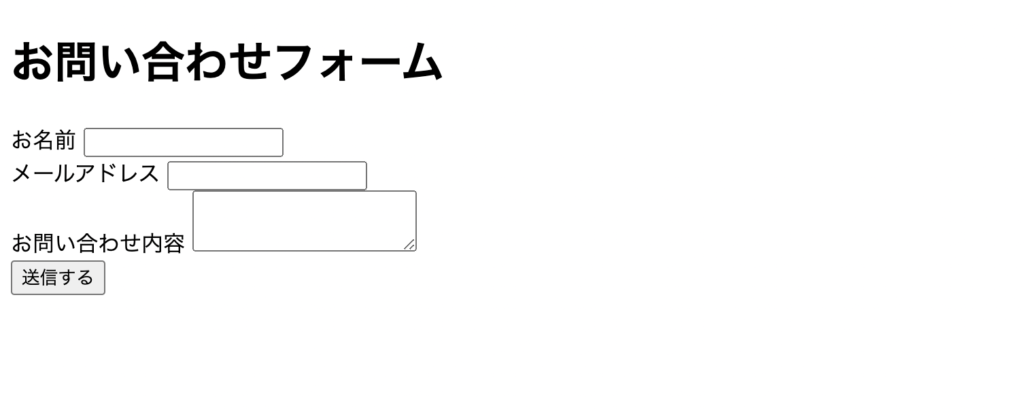
フォームの中身は以下のHTMLです。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>お問い合わせフォーム</title>
</head>
<body>
<h1>お問い合わせフォーム</h1>
<form>
<div>
<label for="name">お名前</label>
<input type="text" id="name" name="name">
</div>
<div>
<label for="email">メールアドレス</label>
<input type="email" id="email" name="email">
</div>
<button type="submit">送信する</button>
</form>
</body>
</html>6.1. PyAutoGUIをインストールする
はじめにPyAutoGUIをインストールします。
pipコマンドでインストールできます。
pip install pyautogui6.2. フォームの入力欄とボタンの画像を用意する
PyAutoGUIを使ってフォームのinputとbuttonを画像で探索して操作します。
事前にブラウザでフォームを表示して、クリックしたい入力欄やボタンをスクリーンショットしておきます。
今回は「お名前(name_input.png)」「メールアドレス(email_input.png)」「送信(submit.png)」の3箇所のスクリーンショットを以下のように撮影し、Pythonファイルを同じディレクトリに保存します。



6.3. 入力欄をクリックして内容を入力
上記で保存したスクリーンショットを頼りにマウスを操作し、入力欄をクリックし、テキストを入力します。
画面内の画像を探索してクリックさせるにはpyautogui.locateCenterOnScreenを使用します。
引数に画像のパスを渡すと、スクリーン内から該当する要素を探し出して、その中心座標を返します。
座標値はx, yで返ってきます。
※Retinaディスプレイ搭載のMacの場合、1つの論理ピクセルに対して2つの物理ピクセルを持っており、x, yの値が2倍になっているため、それぞれ2で割って使用します。
import pyautogui
import pyperclip
# フォームに入力するテキスト
name = "山田 太郎"
email = "yamada@example.com"
# 「お名前」のテキストボックスの画像を検索してクリックさせる
x, y = pyautogui.locateCenterOnScreen("name_input.png")
# テキストボックスに名前を入力する
pyautogui.doubleClick(x / 2, y / 2) # テキストボックスをダブルクリック
# pyautogui.doubleClick(x, y) # Windowsの場合
pyperclip.copy(name) # 日本語を入力するためクリップボードに変数の値をコピーする
pyautogui.hotkey('command', 'v')
# pyautogui.hotkey('ctrl', 'v') # Windowsの場合
# 「メールアドレス」のテキストボックスの画像を検索してクリックさせる
x, y = pyautogui.locateCenterOnScreen("email_input.png")
# テキストボックスにメールアドレスを入力する
pyautogui.doubleClick(x / 2, y / 2) # テキストボックスをダブルクリック
# pyautogui.doubleClick(x, y) # Windowsの場合
pyperclip.copy(email)
pyautogui.hotkey('command', 'v')
# pyautogui.hotkey('ctrl', 'v') # Windowsの場合
日本語でテキストを入力する場合は、入力したいテキストをいったんクリップボードに保存して、それをペーストします。
pyperclip.copy('テキスト') でクリップボードにテキストをコピーし、pyautogui.hotkey('command', 'v')でペーストします。
6.4. 送信ボタンをクリックさせる
最後に送信ボタンをクリックします。
ボタンのクリックは pyautogui.click(x座標, y座標) で実行できます。
# 送信ボタンをクリックする
x, y = pyautogui.locateCenterOnScreen("submit.png")
pyautogui.click(x / 2, y / 2) # 送信ボタンの座標注意点
上記のコードはブラウザでフォームを開いた状態で実行する必要があります。
事前に用意した画像に依存するため、フォームのサイズやデザインが変わると動作しなくなる場合があります。
またPyAutoGUIの使用中はマウスやキーボードを操作できなくなることにも注意しましょう。
WEBフォームの操作をより安定的に自動化したい場合は、JavaScriptとSeleniumを使うと確実です。
7. メール送信の自動化
顧客のメールアドレスリストに対して一括してメールを送信したいことがありますよね?
そんなときもPythonが使えます。
Pythonにはメールの送受信にかかわるモジュールがあらかじめ組み込まれています。
Pythonのリストに含まれるメールアドレスに一括でメールを送信したり、それらのうち特定の条件に当てはまるアドレスにだけ別のメールを送信したりできます。
ここではPythonとGmailを使ってメール送信を自動化するコードを書いてみましょう。
以下が完成形のコードです。
import smtplib
from email.mime.text import MIMEText
from email.utils import formatdate
# あなたのGmailアカウント情報
gmail_account = 'YOUR_GMAIL_ADDRESS@gmail.com'
gmail_password = 'アプリパスワード' # ここに後述するアプリパスワードを入力します
# 送信先のメールアドレス
to_address = 'TO_EMAIL_ADDRESS'
# メールの内容を設定する
subject = 'メール送信のテスト'
body = 'Pythonからのメール送信テストです。'
msg = MIMEText(body)
msg['Subject'] = subject
msg['From'] = gmail_account
msg['To'] = to_address
msg['Date'] = formatdate()
# SMTPサーバーに接続してメールを送信する
smtp_server = 'smtp.gmail.com'
smtp_port = 587
smtp = smtplib.SMTP(smtp_server, smtp_port)
smtp.ehlo()
smtp.starttls()
smtp.login(gmail_account, gmail_password)
smtp.sendmail(gmail_account, to_address, msg.as_string())
smtp.quit()7.1. 必要なモジュールをimportする
はじめにメール送信の自動化に必要なモジュールを読み込みます。
メール送信にはsmtplibモジュールを使います。
また、メールの設定のためにemailモジュールを使用します。
import smtplib
from email.mime.text import MIMEText
from email.utils import formatdate7.2. メールの送信設定を書く
次にメールの送信設定を書きます。
今回はGmailを経由してメール送信を自動化するので、Gmailのアドレスとパスワードを書きます。
パスワードには後述する「アプリパスワード」を設定します。最後に設定するので、いまは書かなくて大丈夫です。
また「送信先のメールアドレス」「メールの件名・本文」を書いておきます。
# あなたのGmailアカウント情報
gmail_account = 'YOUR_GMAIL_ADDRESS@gmail.com'
gmail_password = 'アプリパスワード'
# 送信先のメールアドレス
to_address = 'TO_EMAIL_ADDRESS'
# メールの内容を設定する
subject = 'メール送信のテスト'
body = 'Pythonからのメール送信テストです。'
msg = MIMEText(body)
msg['Subject'] = subject
msg['From'] = gmail_account
msg['To'] = to_address
msg['Date'] = formatdate()7.3. SMTPサーバーの設定を記述する
続いてSMTPサーバーの設定を記述します。
SMTPサーバーとは、メールを送信した際に、メールの送信を中継してくれるサーバーです。
郵便局の受付のようなものです。
今回はGmailを使用するのでGmailが提供しているSMTPサーバー(smtp.gmail.com)を使います。
# SMTPサーバーに接続してメールを送信する
smtp_server = 'smtp.gmail.com'
smtp_port = 587
smtp = smtplib.SMTP(smtp_server, smtp_port)
smtp.ehlo()
smtp.starttls()
smtp.login(gmail_account, gmail_password)
smtp.sendmail(gmail_account, to_address, msg.as_string())
smtp.quit()後はGmailのアプリパスワードを設定すれば、メールを送信できるようになります。
7.4. Gmailのアプリパスワードを設定する
最後にGmailの「アプリパスワード」を設定します。
アプリパスワードとは、任意のアプリからGmailへのログインを許可するためのパスワードです。
アプリパスワードを発行するためにGoogleアカウントのマイページに移動します。
マイページの画面上部に「Googleアカウントを検索」という検索ボックスがあるので、ここに「アプリパスワード」と入力して出てきた候補をクリックします。
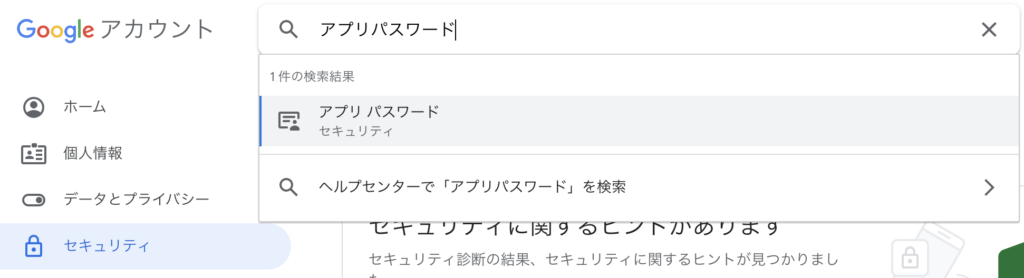
アプリパスワードの画面で「アプリを選択」→「メール」、「デバイスを選択」→「(使用するデバイス)」を選択します。
デバイスはお使いのものを選択します。
以下の画像ではMacを選択しています。
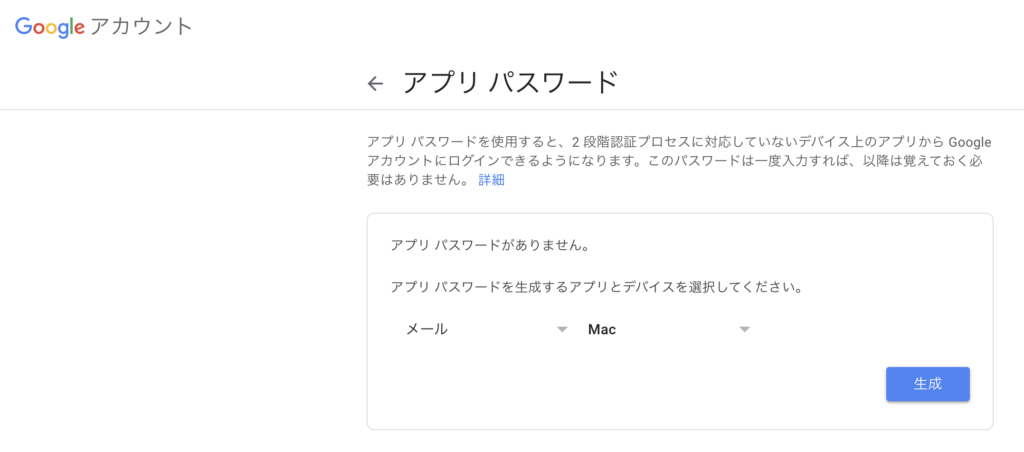
「生成」をクリックするとパスワードが表示されます。
これをコピーして、先ほどのPythonコードの「アプリパスワード(gmail_password)」に設定しましょう。
gmail_password = '生成されたアプリパスワード'5. コードを実行してメールを送信する
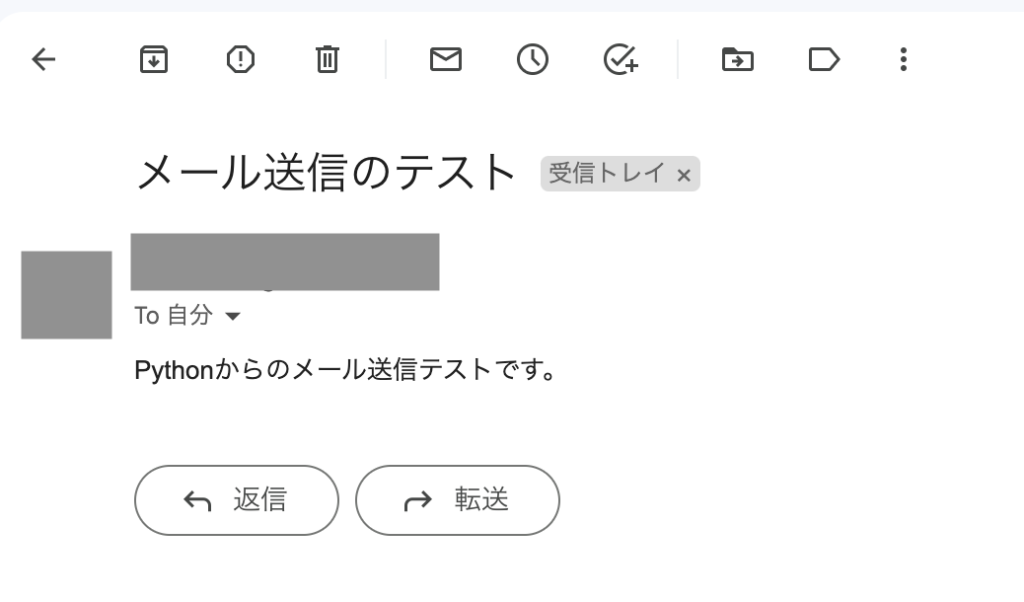
あとはPythonコードを実行するだけです。
テストのために、最初は送信先を自分自身のメールアドレスに設定しておくと安心です。
送信先に設定したメールアドレスにメールが送信されます。
まとめ
この記事ではPythonで自動化できる7つのことを紹介しました。
サンプルコードはどれもコピー・ペーストで使えます。
自分の目的に合うように改良して使ってみてください。


,-function%20to%20get){kind=link}