LangChainの「Output Parser」はLLMの応答をJSONなどの構造化されたデータに変換・解析するための機能です。
LLMの応答は自然言語で返されるため、システムに組み込みにくい場合があります。
たとえば、ChatGPTに「出力をJSONにする指示」を出してみましょう。
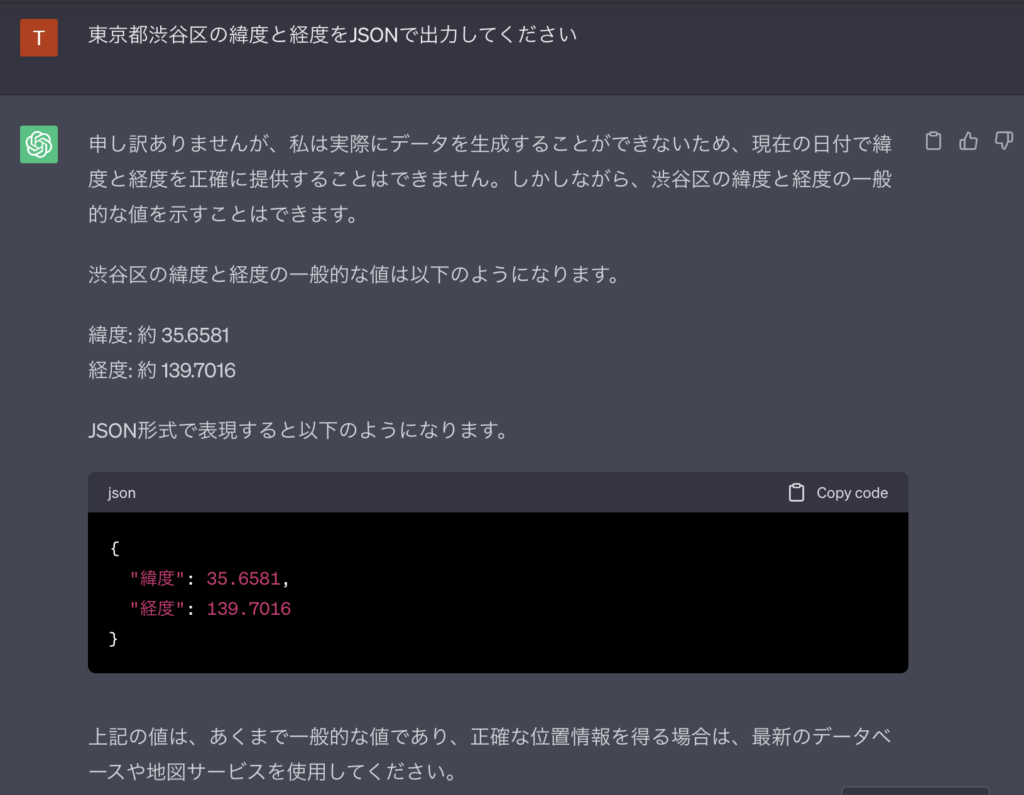
「JSONで出力してください」と指示を出しているため応答にはJSONデータが含まれています。
しかし、JSONデータ以外にも自然言語による説明が入っています。
この応答をシステムで扱うには、応答からJSON部分を抽出し、型をチェックする必要があります。
こうした手続を効率的に行えるようにするのがLangChainの「Output Parser」です。
この記事ではOutput Parserの使い方を詳しく解説します。
Output Parserの概要
LangChainのOutput Parserは、以下のような流れでLLMに構造化データを出力させます。
- LLMに出力させるデータの型を定義する
- 型に則った出力をさせるための「フォーマット命令(format instruction)」を作る
- フォーマット命令とプロンプトを合体してLLMに渡す
- LLMのレスポンスを構文解析する
まず、出力するデータの型を定義します。規定の型として「List」「Datetime」「Enum」がありますが、JSONで独自の型を定義することもできます。
次に、定義した型で出力させるためのフォーマット命令(format instruction)を作成します。これはOutput Parserが勝手にやってくれます。
フォーマット命令ができたら、プロンプトとまとめてLLMに渡します。
LLMから応答が返ってきたら応答を構文解析して、定義した型に変換します。
Output Parserの種類
OutputParserには、以下の7種類(5 + 2種類)があります。
型変換のためのOutput Parser(5種類)
- List parser … LLMのレスポンスをList型に変換したいときに使う
- Datetime parser … LLMのレスポンスをDatetime型に変換したいときに使う
- Enum parser … LLMのレスポンスをEnum型に変換したいときに使う
- Pydantic (JSON) parser … LLMのレスポンスをJSON(Pydanticで構築したデータモデル)に変換したいときに使う
- Structured output parser … Pydantic (JSON) parserのシンプルな版
例外処理のためのOutput Parser(2種類)
- Auto-fixing parser … LLMの応答を指定した型に変換できないときに別のLLMに修正依頼を出すために使う
- Retry parser … LLMの応答を指定した型に変換できないときに別のLLMにやり直させるために使う
前半の5つ(List parserからStructured output parserまで)は、決まった型に出力するためのパーサーです。Output Parserそのものです。
後半の2つ(Auto-fixing parserとRetry parser)は、前半のパーサーで変換ができなかった場合に、修正するためのパーサーです。前半のパーサーをラップする形で使います。それぞれの詳細と違いは後述します。
Output Parserの使い方
ここからはStructured output parserを例にOutput Parserの使い方を説明します。
他のOutputParserも使い方はほぼ同じです。
1. ライブラリをimportする
はじめにライブラリをimportします。
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI2. 応答の型を定義する
次に応答の型を定義します。
LLMに返して欲しいデータの型です。
ここではLLMに架空の企業情報を生成させ「架空の企業名(company_name)」と「代表者名(key_person)」をキーに持つ辞書を返してもらうことにします。
# 応答の型を定義する
response_schemas = [
ResponseSchema(name="company_name", description="架空の企業名"),
ResponseSchema(name="key_person", description="代表者名")
]ResponseSchemaオブジェクトのnameにキーを、descriptionに説明を渡します。
これらをリストにして変数「response_schemas」に入れておきます。
3. Output Parserを用意する
次にOutput Parserを用意します。
# OutputParserを用意する(定義した型を渡す)
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)StructuredOutputParserオブジェクトのfrom_response_schemasメソッドに先ほどの型定義(response_schemas)を渡すだけです。
4. format instructionsを作成する
次にformat instructionsを作成します。
# OutputParserからフォーマット命令を作成する
format_instructions = output_parser.get_format_instructions()
print(format_instructions)format instructionsは「応答の型を指示するためのプロンプト」です。
get_format_instructionsというメソッドを呼び出せば、OutputParserが自動的に作成してくれます。
get_format_instructionsの戻り値はただのテキスト(プロンプト)です。
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
```json
{
"company_name": string // 架空の企業名
"key_person": string // 代表者名
}
```こちらで用意した型定義に沿って、OutputParserが型を指定するプロンプトを作成してくれます。
5. プロンプトを作成する
LLMに渡すプロンプトの全体を作成します。
PromptTemplateのtemplateにメインのプロンプトを渡し、partial_variablesに{"format_instructions": format_instructions}という形で先ほど作成したフォーマット命令のプロンプトを渡します。
# プロンプトを作成する
prompt_template = PromptTemplate(
template="架空の企業を日本語で挙げてください。\n{format_instructions}",
input_variables=[],
partial_variables={"format_instructions": format_instructions}
)
prompt = prompt_template.format_prompt()6. モデルの出力を得る
プロンプトが完成したらLLMにプロンプトを渡して、出力を得ます。
# LLMを準備
model = OpenAI(openai_api_key=OPENAI_API_KEY)
# モデルの出力を得る
output = model(prompt.to_string())
print(output)モデルの出力にはマークダウンで次のようなJSONデータが入っているはずです。
```json
{
"company_name": "イートゥースティー",
"key_person": "山田太郎"
}
```7. モデルの出力の構文解析して辞書型に変換する
最後にモデルの出力を辞書型に変換します。
OutputParserのparseメソッドにモデルの出力を渡すだけです。
# 出力をパースする
result = output_parser.parse(output)
print(result)うまくいけば出力が辞書型に変換できるはずです。
{'company_name': 'イートゥースティー', 'key_person': '山田太郎'}データの変換で例外が発生する場合
LangChainのOutputParserはLLMの出力を解析しますが、必ずしもうまく変換できるわけではありません。変換できなかった場合は、以下のような例外が発生します。
langchain.schema.output_parser.OutputParserException: Got invalid JSON object. Error: Extra data: line 5 column 1 (char 75)これはLLMの出力が正しいJSON構造にならなかった場合に発生します。
例外が発生した場合は、後述の「Auto-fixing parser」や「Retry parser」を使ってLLMに修正依頼をかけることで解消します。
ここからは残りの6つのOutput Parserについて順に説明します。
List parser(CommaSeparatedListOutputParser)
ListParserは、LLMの応答をリスト形式で受け取りたいときに使います。
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
# OutputParserを定義
output_parser = CommaSeparatedListOutputParser()
# フォーマットの指示を作成
format_instructions = output_parser.get_format_instructions()
print(f"format_instructions: {format_instructions}") # format_instructions: Your response should be a list of comma separated values, eg: `foo, bar, baz`
# プロンプトのテンプレートを作成
prompt_template = PromptTemplate(
template="以下を5つ列挙してください {subject}.\n{format_instructions}", # プロンプトテンプレート
input_variables=["subject"], # ユーザー入力
partial_variables={"format_instructions": format_instructions} # フォーマットの指示をプロンプトに設定
)
# LLMを構築
model = OpenAI(openai_api_key=OPENAI_API_KEY)
# プロンプトを作成
prompt = prompt_template.format(subject="日本の有名な都市")
# LLMに応答を出力させる
output = model(prompt)
# 出力を解析
result = output_parser.parse(output)
print(result) # ['東京,大阪,名古屋,札幌,仙台']Output ParserをCommaSeparatedListOutputParser()で定義するだけです。
出力はPythonのリスト型になります。
Datetime parser(DatetimeOutputParser)
Datetime parserは応答をDatetime型で受け取るために使います。
from langchain.output_parsers import DatetimeOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
# OutputParserを定義
output_parser = DatetimeOutputParser()
# フォーマットの指示を作成
format_instructions = output_parser.get_format_instructions()
print(f"format_instructions: {format_instructions}")
# プロンプトのテンプレートを作成
prompt_template = PromptTemplate(
template="OpenAIの誕生日は? .\n{format_instructions}", # プロンプトテンプレート
input_variables=[],
partial_variables={"format_instructions": format_instructions} # フォーマットの指示をプロンプトに設定
)
# LLMを構築
model = OpenAI(openai_api_key=OPENAI_API_KEY)
# プロンプトを作成
prompt = prompt_template.format()
# LLMに応答を出力させる
output = model(prompt)
# 出力を解析
result = output_parser.parse(output)
print(result) # 2015-12-11 00:00:00出力がPythonのDatetime型になります。
Enum parser(EnumOutputParser)
Enum parserは応答をEnumで受け取るために使います。
from langchain.output_parsers.enum import EnumOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
# 事前にEnumで型を定義
from enum import Enum
class Animal(Enum):
RED = "red"
BLUE = "blue"
GREEN = "green"
# OutputParserを定義
output_parser = EnumOutputParser(enum=Animal) # Enumオブジェクトを引数に渡す
# フォーマットの指示を作成
format_instructions = output_parser.get_format_instructions()
print(f"format_instructions: {format_instructions}") # format_instructions: Select one of the following options: red, blue, green
# プロンプトのテンプレートを作成
prompt_template = PromptTemplate(
template="#ff0000は何色? .\n{format_instructions}", # プロンプトテンプレート
input_variables=[],
partial_variables={"format_instructions": format_instructions} # フォーマットの指示をプロンプトに設定
)
# LLMを構築
model = OpenAI(openai_api_key=OPENAI_API_KEY)
# プロンプトを作成
prompt = prompt_template.format()
# LLMに応答を出力させる
output = model(prompt)
print(output)
# 出力を解析
result = output_parser.parse(output)
print(result) # Animal.REDEnumで定義したいずれかの値で応答するように指示します。
筆者が試したところEnum parserは他のOutput Parserに比べて例外(OutputParserException)が発生しやすく、あまりうまくいきませんでした。特に、Enumで定義した以外の値がLLMの応答に含まれることが多く、例外が頻発しました。
Pydantic (JSON) parser
Pydantic (JSON) parserは、LLMの応答をPydanticで指定した型で受け取るために使います。
データ構造を自由に定義できるため、もっとも実用的なOutput Parserかもしれません。
PydanticはPythonでデータモデルを作るためのライブラリです。
クラスで型を定義して型ヒントやバリデーションの設定が簡単にできます。
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
# Pydanticで型を定義する
class Company(BaseModel):
name: str = Field(description="企業名")
key_person: str = Field(description="代表者")
address: str = Field(description="所在地")
# OutputParserを定義する
parser = PydanticOutputParser(pydantic_object=Company)
# プロンプトを作成
prompt_template = PromptTemplate(
template="架空の企業を日本語で生成してください\n{format_instructions}\n",
input_variables=[],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
prompt = prompt_template.format_prompt()
# LLMを準備
model = OpenAI(openai_api_key=OPENAI_API_KEY)
# 応答を得る
output = model(prompt.to_string())
# 応答を構文解析
result = parser.parse(output)
print(result) # name='テクノソリューション株式会社' key_person='田中太郎' address='東京都港区'PydanticではBaseModelを継承したクラスとして型を定義します。
詳しくはPydanticのサイトを確認してください。
型の定義以外の手続きは他のOutput Parserと同じです。
Auto-fixing parser(OutputFixingParser)
Auto-fixing parser(OutputFixingParser)は、これまで紹介してきたOutput Parserとは性質が異なります。
Auto-fixing parserでは、LLMの応答を他のOutput Parserで変換しようとして例外が発生した場合に、別のLLMに修正依頼を出すことができます。
例として、以下の場合を考えてみましょう。
以下の例では、PydanticOutputParserを使って架空の企業情報を生成させて、結果をJSONで受け取ろうとしています。しかし、受け取ったJSONがパースできない形式(misformatted_output)になっていたとします。
class Company(BaseModel):
name: str = Field(description="企業名")
key_person: str = Field(description="代表者")
parser = PydanticOutputParser(pydantic_object=Company)
# 仮に解析できない回答が得られたとする
misformatted_output = "{'name': 'テクノソリューション株式会社', 'key_person': '田中太郎,山本二郎' }"
# フォーマットできない回答をパースしようとする
parser.parse(misformatted_output)
# langchain.schema.output_parser.OutputParserException: Failed to parse Company from completion ...
パースできない応答を無理やりパースしようとすると例外(OutputParserException)が発生します。
このような例外が発生する可能性があるとき、PydanticOutputParserをOutputFixingParserでラップしておくと、例外発生時に別のLLMに修正依頼を出すことができます。
class Company(BaseModel):
name: str = Field(description="企業名")
key_person: str = Field(description="代表者")
parser = PydanticOutputParser(pydantic_object=Company)
# 追加: OutputFixingParserでPydanticOutputParserをラップする
output_fixing_parser = OutputFixingParser.from_llm(
parser=parser,
llm=ChatOpenAI(openai_api_key=OPENAI_API_KEY)
)
misformatted_output = "{'name': 'テクノソリューション株式会社', 'key_person': '田中太郎,山本二郎' }"
# 追加: OutputFixingParserでパースする
result = output_fixing_parser.parse(misformatted_output)
print(result) # name='テクノソリューション株式会社' key_person='田中太郎, 山本二郎'ここでは、例外が発生した場合にChatOpenAIに修正依頼を出して修正させています。
これによってエラーが修正され、正しくパースできるようになります。
OutputFixingParserは、例外発生時に「LLMの(間違った)出力」と「例外の内容」と「フォーマット命令(format instructions)」を別のLLMに投げます。
これらの情報を使って新しいLLMが修正してその応答を再度パースするという流れになります。
Retry parser(RetryWithErrorOutputParser)
Retry parserもOutputFixingParserと同様に、例外発生時にLLMに修正依頼を出すために使用します。
OutputFixingParserとの違いは例外発生時に新しいLLMに渡す情報の種類です。
OutputFixingParserは、例外発生時に「LLMの出力」「例外の内容」「フォーマット命令(format instructions)」の3つの情報を渡しますが、RetryWithErrorOutputParserは「LLMの出力」「例外の内容」と「プロンプト全体」を渡します。「プロンプト全体」にはフォーマット命令も含まれます。
フォーマット命令だけでなくプロンプトの全体とエラーをまとめてLLMに修正依頼をするので修正の質がよくなります。
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain.output_parsers import (
PydanticOutputParser,
)
from pydantic import BaseModel, Field
class Company(BaseModel):
name: str = Field(description="企業名")
key_person: str = Field(description="代表者")
# OutputParserを定義
parser = PydanticOutputParser(pydantic_object=Company)
# プロンプトを作成
prompt_template = PromptTemplate(
template="架空の企業を日本語で生成してください。\n{format_instructions}",
input_variables=[],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
prompt = prompt_template.format_prompt()
# 仮に誤った応答が得られたとする
bad_response = '{"name": "key_person"}'
# parser.parse(bad_response) # langchain.schema.output_parser.OutputParserException: ...
# これは単なる構文エラーではないためOutputFixinParserで修正が難しい
# fix_parser = OutputFixingParser.from_llm(parser=parser, llm=OpenAI(openai_api_key=OPENAI_API_KEY))
# result = fix_parser.parse(bad_response)
# print(result)
from langchain.output_parsers import RetryWithErrorOutputParser
# RetryWithErrorOutputParserはプロンプトとエラー内容をもとに応答を修正する
retry_parser = RetryWithErrorOutputParser.from_llm(
parser=parser,
llm=OpenAI(openai_api_key=OPENAI_API_KEY)
)
result = retry_parser.parse_with_prompt(bad_response, prompt)
print(result)OutputFixingParserとRetryWithErrorOutputParserの使い分けは難しいところですが、基本的にRetryWithErrorOutputParserを使えば間違いないような気がします。
あえてOutputFixingParserを使うべき場面があれば教えてください。
まとめ
この記事では、LangChainのOutput Parserの使い方を解説しました。
LLMの回答を指定のデータ構造に変換することは、システムにLLMを組み込むために超重要な機能です。
特にLLMの出力を修正させるAuto-fixing parserやRetry parserはかなり便利な機能だと思います。
ぜひ使ってみてください。