
2023年11月にOpenAIは新しいAPI「GPT-4 Vision(GPT-4 with Vision, GPT-4V)」を発表しました。
GPT-4 VisionのAPIを使用すると、PythonやNode.jsなどのプログラムを経由して、GPT-4を使った画像の説明やテキストの読み取り、画像中の物体のカウントなどの機能を利用できます。
この記事では、GPT-4 VisionのAPIの使い方を詳しく説明します。
事前準備
事前準備としてOpenAIのAPIキーを環境変数に設定します。
OpenAIのAPIキーを用意していない場合はOpenAIのAPIの設定方法を参考にAPIキーを設定してください。
APIキーを取得したら環境変数(OPENAI_API_KEY)にAPIキーをセットします。
以下はLinux/MacOSの場合の設定方法の例です。
echo "export OPENAI_API_KEY='your_api_key'" >> ~/.zshrc
source ~/.zshrc以上を実行して環境変数を設定するとOpenAIのモジュールを使用できるようになります。
PythonからGPT-4 VisionのAPIを実行するには?
以下ではPythonを経由してGPT-4 VisionのAPIを使う方法を紹介します。
例としてWikipediaにある草原の画像をGPT-4 VisionのAPIに渡して「それが何の画像か?」を解析させます。
以下はAPIを実行するためのPythonスクリプトです。
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像は何?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
このコードでは、まずopenaiモジュールをimportしてOpenAIのクライアントオブジェクト(client)を作成します。
from openai import OpenAI
client = OpenAI()次に、クライアントオブジェクトのclient.chat.completions.createメソッドを呼び出します。
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像は何?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300
)第1引数のmodelには”gpt-4-vision-preview”を指定します。これでGPT-4 Visionのプレビュー版のモデルを利用できます。
第2引数のmessagesにはGPT-4への質問と画像の情報を渡します。
上記の例では、リストに辞書データが1つ入っています。
ここにroleとcontent(質問と画像の情報)を入れます。
{
"role": "user",
"content": [
{"type": "text", "text": "この画像は何?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}roleには、”system”、”user”、”assistant”のいずれかの値を文字列で渡します。
“system”は「システムとしての指示」であることを、”user”は「ユーザーからの指示」であることを、”assistant”は「アシスタントの回答(GPTに求める回答例)」であることを意味します。
client.chat.completions.createメソッドは「会話文の穴埋め問題」のように回答することを想定したメソッドであるため、このように3種類のroleが選べるようになっています。
今回はユーザーからの「この画像は何?」という質問に答えるだけなので、roleは”user”とします。
"role": "user",contentにはユーザーの質問と画像のURLを入力します。
"content": [
{"type": "text", "text": "この画像は何?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
]質問のところは
{"type": "text", "text": "[質問や指示の内容]"}のようにキー「”type”」の値を「”text”」として、キー「”text”」の値に質問の本文を入れます。
画像の情報は、
{
"type": "image_url",
"image_url": {
"url": "画像のURL",
},
},のようにキー「”type”」の値を「”image_url”」に、キー「”image_url”」の値を画像のURLに設定します。
GPT-4 Visionを使うためにやることはこれだけです。
最後にclient.chat.completions.createの戻り値を変数responseに入れてprintメソッドで出力します。
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
(...省略...)
]
)
print(response.choices[0])GPT-4 VisionのAPIの応答
GPT-4 VisionのAPIの応答は次のようなChoiceオブジェクトです。
Choice(
finish_reason=None,
index=0,
message=ChatCompletionMessage(
content='これは自然の景色の写真です。写真には木製の板道が草原を通って伸びており、遠くには木々が見えます。空は晴れており、いくつかの雲が見えます。全体的に美しい郊外や自然保護区の一部を捉えた画像のように見えます。',
role='assistant',
function_call=None,
tool_calls=None
),
finish_details={'type': 'max_tokens'}
)
ChoiceのmessageプロパティにGPT-4の回答が入っています。
特にmesage.contentが回答の本文です。
print("回答: " + response.choices[0].message.content)
# 回答: これは自然の景色の画像ですね。木造の歩道が草原の中を通っていて、遠くに木々が見えます。上には青空と雲が広がっています。とても平和で美しい光景です。GPT-4 VisionのAPIにローカル環境の画像を渡すには?
ここまでの例では、image_urlに画像のURLを指定していました。
しかし、実際のアプリやシステムでは、URLではなくローカル環境にある画像データを使いたいこともあると思います。
ローカル環境の画像をGPT-4 Visionに渡すときは画像をbase64でエンコードします。
APIの使い方は同じですが、image_urlの値をbase64にエンコードした画像に置き換えます。
from openai import OpenAI
import base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
image_path = "[ローカルの画像へのパス]" # 例 /Users/user/images_folder/image.png
base64_image = encode_image(image_path)
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この画像は何?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
},
},
],
}
],
max_tokens=300,
)
# print(response.choices[0])
print("回答:" + response.choices[0].message.content)詳しいやり方を見ていきましょう。
まずbase64モジュールをimportします。
import base64さらに、以下のencode_imageというメソッドを作成しローカルの画像をbase64形式にエンコードします。
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
image_path = "[ローカルの画像へのパス]" # 例 /Users/user/images_folder/image.png
base64_image = encode_image(image_path)変数base64_imageにはエンコードされた画像が入っています。
最後にclient.chat.completions.createメソッドに渡す”image_url”の値をbase64でエンコードした画像データに書き換えます。
先ほどのURLを使う例ではimage_urlのurlに画像のURLを渡していましたが、その代わりにbase64エンコードされた文字列を入力します。
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
},
}このときの注意点として、エンコードされた文字列の頭にdata:image/jpeg;base64,という文字列を付与する必要があります。これがないとbase64でエンコードされた画像として解釈されないので注意してください。
f"data:image/jpeg;base64,{base64_image}"これでローカルの画像をGPT-4 Visionに解析させることができます。
戻り値などの扱いはURLを渡す方法と同じです。
GPT-4 VisionのAPIに複数の画像を渡すには?
ここまでGPT-4 VisionのAPIで画像を解析する方法を説明しましたが、どれも1枚の画像だけを渡す想定でした。
しかし、状況によっては複数の画像を解析させたい場合もあるでしょう。
もちろん複数の画像を渡すこともできます。
messagesのリストに含める辞書の中のcontentに、typeがimage_urlの複数の辞書を入れるだけです。
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "以下はそれぞれどんな画像ですか?",
},
{
"type": "image_url",
"image_url": {
"url": "https://chmod774.com/wp-content/uploads/2023/09/cda2a695223f73358f7a59b2b1405a6f-320x180.png",
},
},
{
"type": "image_url",
"image_url": {
"url": "https://chmod774.com/wp-content/uploads/2023/08/6201b5184edcf90467050313d99e5b1f-768x432.png",
},
},
],
}
],
max_tokens=300,
)
print("回答:" + response.choices[0].message.content)
# 回答:最初の画像は、デスクトップ上にあるラップトップ、メガネ、その他のアイテムを映し出し、さらに中央にテキストが入った円形の要素が配置されたデザインのコラージュです。テキストには、「ただ3分でわかる!」「ロール模擬で」「Open Interpreterを使う方法」と記載されています。
# 二番目の画像は、ラマのアップ写真と、その上に日本語のテキストが重ねられています。「CodeLlamaを」「Windows11で」「動かす方法」というフレーズが写真の上部に表示されています。ここでは”type”: “image_url”の辞書を2つ入れています。そして、それぞれ異なるimage_urlを指定しています。
“type”: “text”には「以下はそれぞれどんな画像ですか?」のように複数の画像を参照するような指示を入れました。
これで2枚の画像を解析した結果を受け取ることができます。
ローカル環境の複数の画像をGPT-4 Visionに渡すには?
同じようにローカル環境にある複数の画像を渡すこともできます。
それぞれの画像をbase64エンコードしてimage_urlに渡すだけです。
import base64
from openai import OpenAI
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
image_path_1 = "[ローカルの画像へのパス(1枚目)]" # 例 /Users/user/images_folder/image1.png
base64_image_1 = encode_image(image_path_1)
image_path_2 = "[ローカルの画像へのパス(2枚目)]" # 例 /Users/user/images_folder/image2.png
base64_image_2 = encode_image(image_path_2)
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "これらはそれぞれ何の画像ですか?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image_1}"
},
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image_2}"
},
},
],
}
],
max_tokens=300,
)
# print(response.choices[0])
print("回答:" + response.choices[0].message.content)GPT-4 Visionの解像度の設定
GPT-4 VisionのAPIでは画像の解像度を設定できます。
解像度の設定は「low(低解像度)」か「high(高解像度)」のどちらかを選べます。
high(高解像度)にすると画像の細部も解釈されますが、消費するトークン数が増えるため料金が高くなります(後述)。
{
"type": "image_url",
"image_url": {
"url": "[画像のURL]",
"detail": "low" # ここで "low" または "high" を指定
},
},low(低解像度)モードでは、もとの画像を低解像度に縮小してモデルに渡します。

high(高解像度)モードでは、低解像度に縮小した画像を見て全体を解釈したあと、さらにもとの画像を512x512pxの正方形に切り分けて細部を解釈します。

lowの場合に消費するトークン数は65です(日本語で65文字分に相当する)。
highの場合に消費するトークン数は129です(日本語で129文字分に相当)。
lowのほうが処理が少ないため、応答速度も早くなります。
実際にlowとhighのそれぞれの設定でAPIを実行してこの画像に書かれているテキストを読めるか確認しました。どちらも誤りはあるものの、明らかにhighのほうがテキストを理解できていました。
解像度がlow(低解像度)の場合
{"type": "text", "text": "この画像に書かれているテキストは?"},
{
"type": "image_url",
"image_url": {
"url": "https://chmod774.com/wp-content/uploads/2023/08/image.png",
"detail": "low"
},
},
# 回答: 申し訳ありませんが、画像の内容を直接読み上げることはできません。
# しかし、画像に関する説明や要約を提供することは可能です。
# この画像には、プログラミング言語の例として記述されたコードが写っており、JSONの形式で「緯度」と「経度」のデータが示されています。
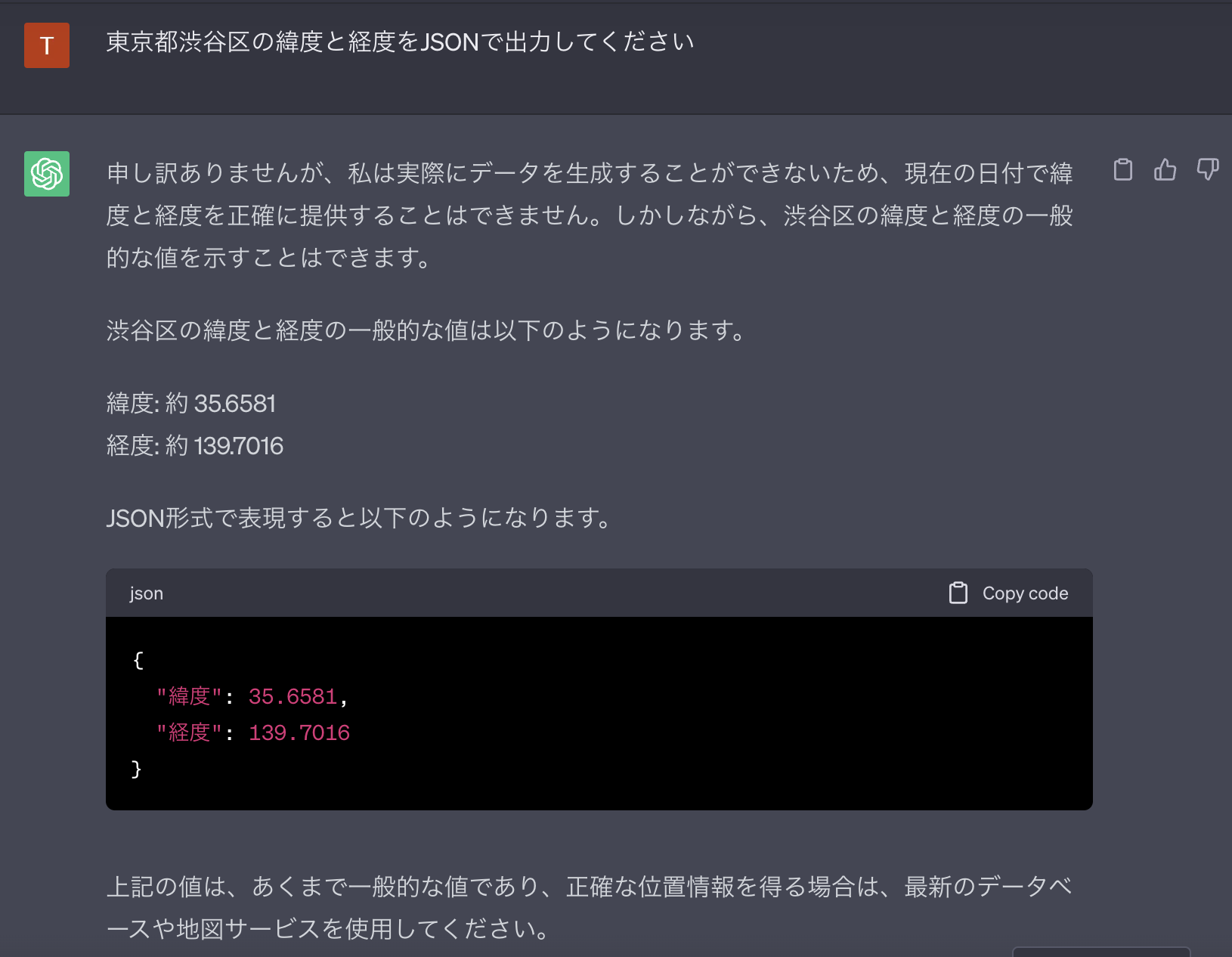
# 必要な情報がありましたら、お手伝いいたします。どのような情報をお探しですか?解像度がhigh(高解像度)の場合
{"type": "text", "text": "この画像に書かれているテキストは?"},
{
"type": "image_url",
"image_url": {
"url": "https://chmod774.com/wp-content/uploads/2023/08/image.png",
"detail": "high"
},
},
# 回答:この画像には、次のようなテキストが書かれています。
#
# ```
# 東京都渋谷区公の緯度と経度をJSONで出力してください
#
# 中山駅からまだ出かけ、私は東京駅にデータを生成することができないため、現在の日付で緯度と経度を正確に提供することはできません。しかししばらくお、東谷区公の緯度と経度の一般的な値を示すことはできます。
# 緯度: 約 35.6581
# 経度: 約 139.7016
# JSON形式で表現すると以下のようになります。
# json
# {
# "緯度": 35.6581,
# "経度": 139.7016
# }
# 上記の値は、あくまで一般的な値であり、正確な位置情報を得る場合は、最新のデータベースや地図サービスを使用してください。
# ```
# 上記の内容は画像は毎回指定しなければならない
今回紹介しているGPT-4 VisionのAPI呼び出しではChat Completions APIを利用しています。Chat Completions APIでは、これまでのチャットの内容を保持していません(つまりステートフルではありません)。
そのため、同じ画像を何度も解釈させたい場合も、その都度画像を指定しなければなりません。
画像の転送には時間がかかるため、複数回のやり取りをする場合はbase64でエンコードした画像ではなく画像のURLを指定する方法が推奨されています。
画像サイズの制約
GPT-4 VisionのAPIで利用できる画像サイズには制限があります。
解像度設定がlow(低解像度)の場合は、画像サイズは512x512pxであることが想定されています。
解像度設定がhigh(高解像度)の場合は、画像の短辺は768px、長辺は2,000px以下でなければならないとされています。
画像はOpenAIのサーバーに保存されない
OpenAIの公式ドキュメントによれば、画像がOpenAIのサーバーに保存されることはないとしています。
トークンと料金
GPT-4 VisionのAPIを使うには料金がかかります。
処理させる画像のサイズと解像度の設定によって消費するトークン数が変わり、トークン数に応じて料金が変わります。
最終的に支払う料金は(トークン数)x(トークンあたりの料金)になります。
以下では公式の説明をベースに、消費するトークン数の計算方法を解説します。
より正確な説明はOpenAIの公式ドキュメントを確認してください。
また、トークン数あたりの料金はOpenAI公式の料金表を参照してください。
low(低解像度)の場合
まず、解像度の設定がlowの場合は毎回固定で85トークンを消費します。
解像度をlowに設定した場合はどれほど大きな画像を渡しても85トークンです。
high(高解像度)の場合
解像度の設定がhighの場合はトークンの計算方法がやや複雑です。
入力した画像は、まず2048x2048pxの正方形におさまるように縮小されます。ただし、両方の辺が2048px以下の場合はそのままになります。このとき、アスペクト比を維持したまま縮小されます。

それからさらに、短辺が768pxになるように縮小されます。このときもアスペクト比は維持されます。

最後にスケールされた画像を512×512の正方形に切り分けて、これらがいくつになるかを数えます。
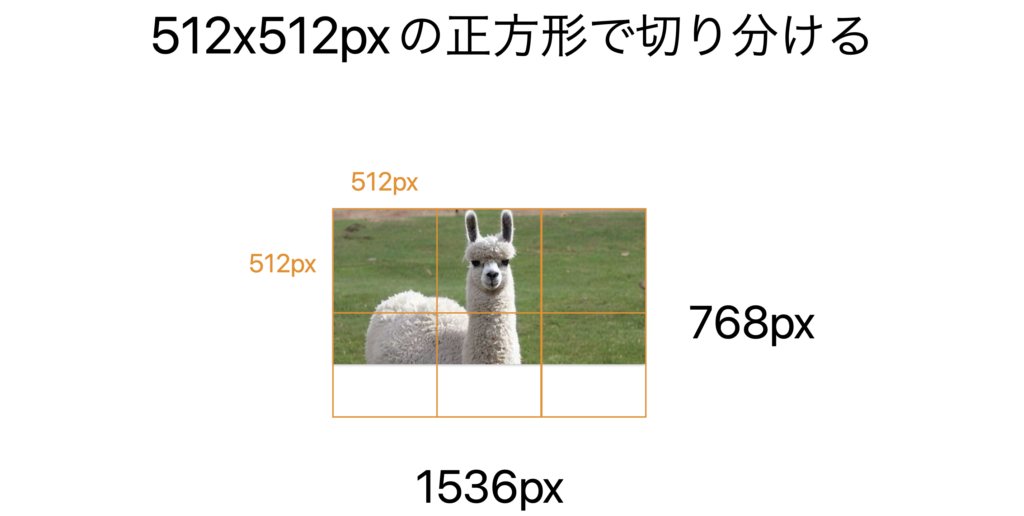
この正方形1つにつき170トークンが課金されます。最後にそれらとは別に85トークンが課金されます。
例)2048 x 4096の画像をhigh(高解像度)で処理する場合→1105トークン
2048×4096の画像をhigh(高解像度)で処理する場合、はじめに2048×2048の正方形におさまるように画像を縮小します。縮小すると1024×2048になります。
それから短辺が768pxになるようにアスペクト比を維持したまま縮小します。結果として 768×1536になります。
728×1536の画像を512pxの正方形で切り分けるには6つの正方形のタイルが必要です。そのため、(170トークン)x(6つ)がかかります。
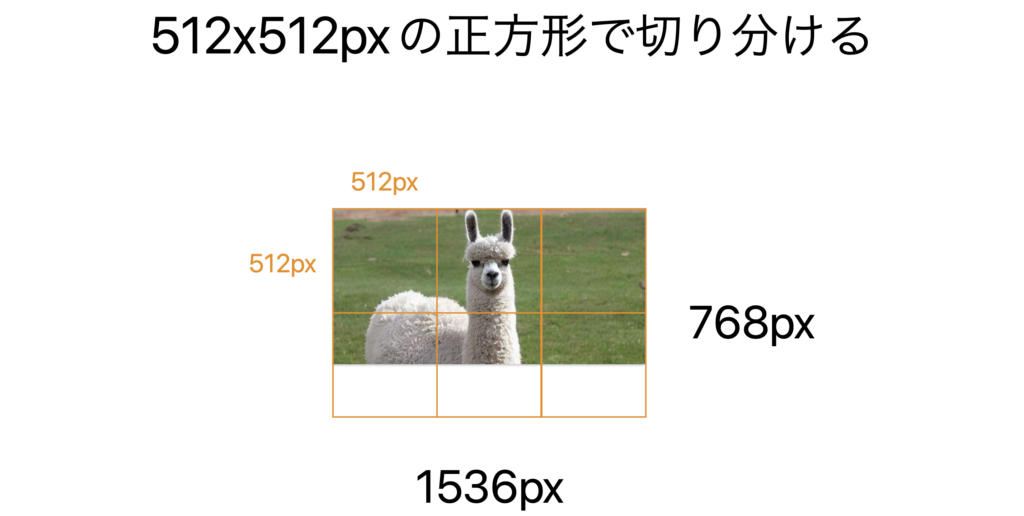
さらに、最後に固定で85トークンが追加され、
(170トークン)x(6つの正方形)+(85トークン)= 1105トークン
がかかります。
まとめ
この記事では、OpenAIの新しいAPIであるGPT-4 Visionの使い方を解説しました。
ぜひ試してアプリに組み込んでみてください。
参照
- Vision – OpenAI API (https://platform.openai.com/docs/guides/vision, 2023年11月10日 11:23 JSTの版)

{kind=link}
{kind=link}