画像生成AIであるStable Diffusionを応用すると、以下のように「しゃべるAI美女」の動画を作ることができます。
これはSadTalkerというオープンソースソフトウェア(MIT license)を使って作ったものです。
話す内容と口の動きが対応していて、リアルなリップシンク動画になっていますね。
この記事では、Stable Diffusion web UI(AUTOMATIC1111)とSadTalkerの拡張機能を使ってこのような「しゃべるAI美女」を作る方法を解説します。
SadTalkerとは?
SadTalkerとは、音声データから顔の3次元的な動きを推定する技術です。
音声データから顔や口元の動きを推定することによって、写真に写る人物の表情を変化させて、あたかもその人が話しているように見せることができます。
2023年に発表され、GitHubにMIT licenseでソースコードも提供されています。
Stable Diffusion web UI(AUTOMATIC1111)の拡張機能としても使用できるので、冒頭で紹介したようなリップシンク動画を簡単に作ることができます。
SadTalkerのインストール
さっそくStable Diffusion web UI(以下、web UI)にSadTalkerの拡張機能をインストールしましょう。
ExtensionsタブのInstall from URLタブにあるURL for extension’s git repositoryに以下のURLを入力してInstallをクリックします。
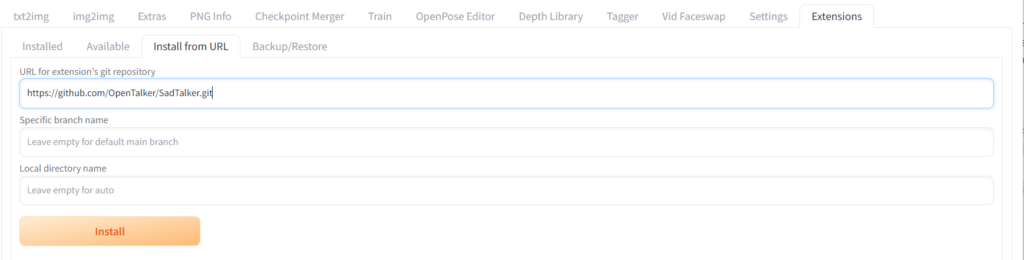
その後、Apply and restart UIをクリックしてUIを更新します。

UIを更新するとSadTalkerのタブがUIに追加されます。
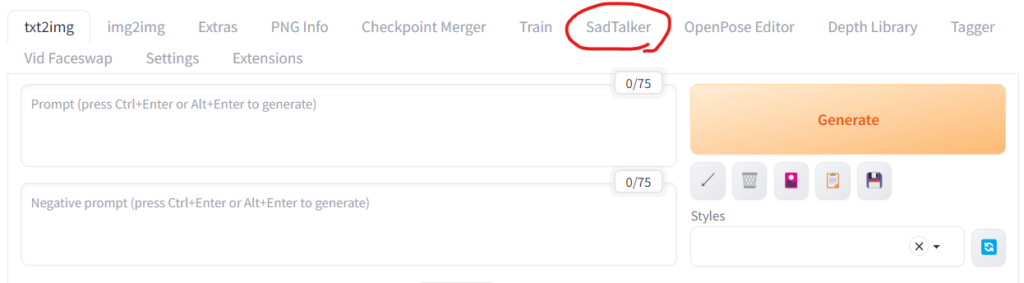
これでSadTalkerの拡張機能のインストールは完了です。
ここでweb UIを一度終了します。
SadTalkerのモデルをダウンロードする
次にSadTalkerのモデルをダウンロードします。
先ほどインストールしたのは拡張機能で、これだけでは使えません。
モデルをダウンロードして設定することで顔の動きを推定できるようにします。
その前に、web UIの「extensions」フォルダにある「SadTalker」フォルダを開き、
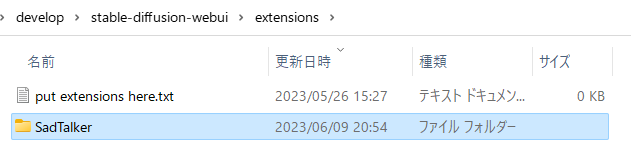
モデルのダウンロード先として「checkpoints」フォルダを作成します。
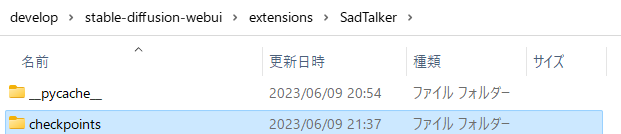
その後、以下のGoogle DriveからSadTalkerのモデルをダウンロードします。

以下の画面が開きますが「すべてダウンロード」をクリックしてまとめてダウンロードします。
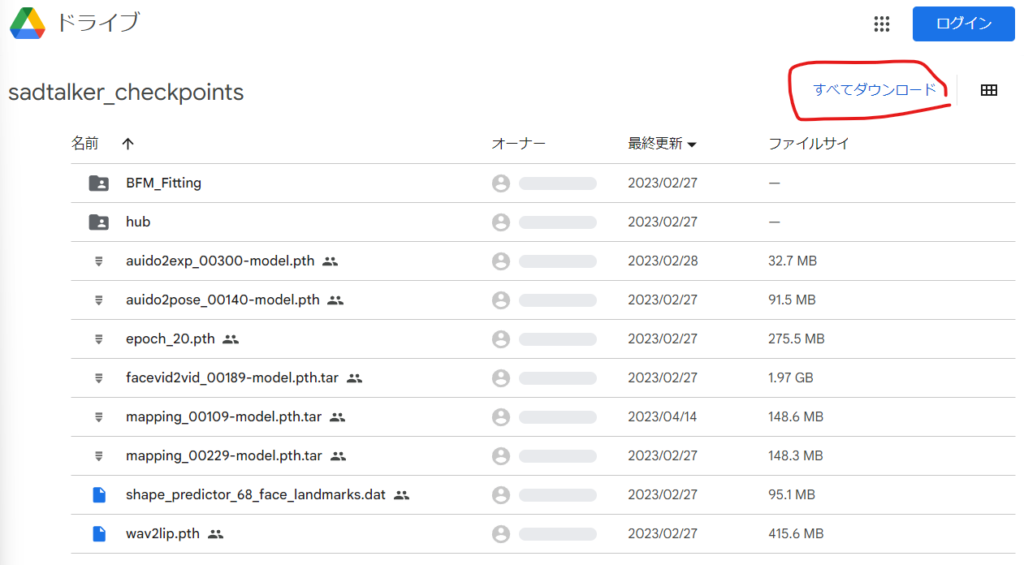
しばらくすると2つのzipファイルがダウンロードされます。
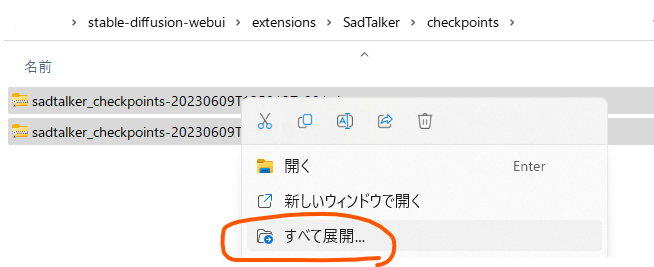
これらをさきほど作成したcheckpointsフォルダに移動して、それぞれ「すべて展開」します。
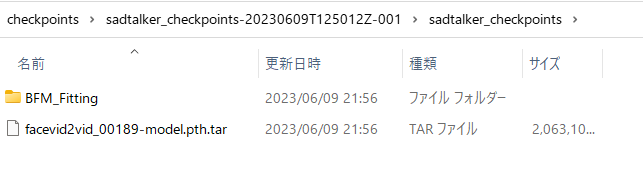
展開したそれぞれのフォルダの中にある以下のファイルをcheckpointsフォルダの直下にすべて移動します。

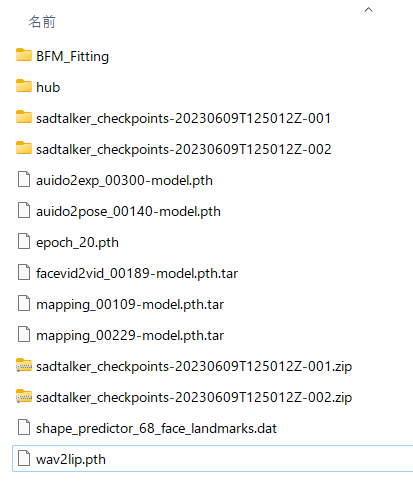
checkpointsフォルダが最終的に以下のようになっていればOKです。
Stable Diffusion web UIにcheckpointsへのパスを教える
続いてweb UIに先ほどの「checkpoints」フォルダの場所を教えます。
これによって、先ほどダウンロードしたモデルをweb UIが読み込めるようになります。
stable-diffusion-web-uiフォルダにあるwebui-user.batファイルをテキストエディタで開きましょう。
右クリックして「編集」で開きます。
以下のようなテキストが開きます。
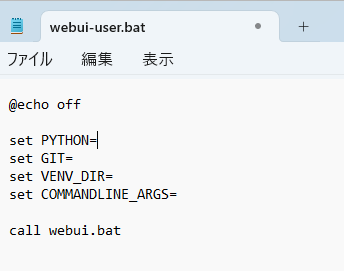
ここで「PYTHON=」の下に以下の1行を追加します。
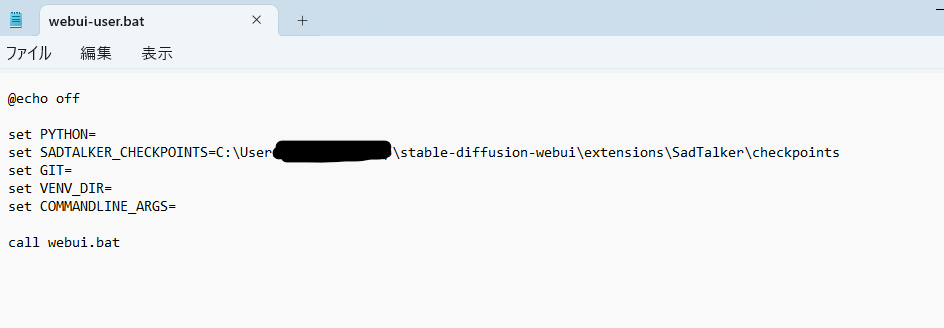
set SADTALKER_CHECKPOINTS=[checkpointsへのパス]ここで[checkpointsへのパス]をcheckpointsフォルダへのパスに置き換えてください。
以下のようになればOKです。
書き込んだら保存して閉じます。
FFmpegをインストールする
最後にFFmpeg(エフエフエムペグ)をインストールします。
FFmpegは動画や音声を扱うためのソフトウェアです。
SadTalkerがFFmpegに依存しているためインストールする必要があります。
以下にアクセスしてFFmpegをダウンロードします。

zipファイルがダウンロードできるので展開します。
ただし、このままでは展開できません。
展開するために7-Zipを使います。

上記のリンクから自分の環境にあったexeファイルをダウンロードして実行し、7-Zipをインストールしましょう。
インストールが完了したら、先ほどダウンロードしたFFmpegの.7zファイルを右クリックしてコンテキストメニューを開き、7-Zip→展開…をクリックします。

展開したら中身をCドライブ直下に移動して、フォルダ名を「ffmpeg」にします。
次にffmpegのフォルダにパスを通します。
「パスを通す」とはWindowsにffmpegの場所を教えてあげて、Windowsがどこからでもffmpegを実行できるようにする作業です。
キーボードのWindowsキーとRキーを同時に押して、cmd.exeと入力します。
それからCtrl+Shift+Enterを押すと管理者の権限でコマンドプロンプトが開きます。

黒い画面が開いたら以下のように入力してEnterキーを押します。
setx /m PATH "C:\ffmpeg\bin;%PATH%"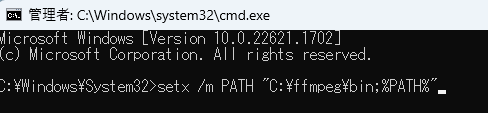
「成功: 指定した値は保存されました。」と表示されればOKです。
SadTalkerの使い方
これでようやくSadTalkerを使えるようになります。
web UIを開きましょう。
web UIを開いたらSadTalkerタブをクリックして開きます。
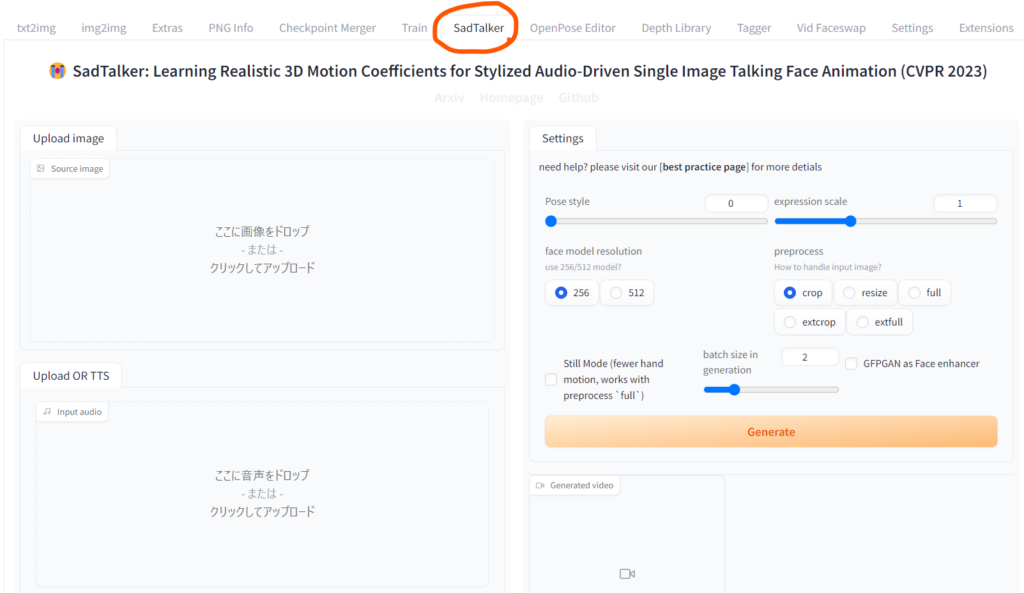
画面の左側上部のスペースが画像をアップロードするスペースです。ここにしゃべらせたい人物の写真をドラッグドロップします。人物の写真は顔の全体がはっきり写っているものが良いです。
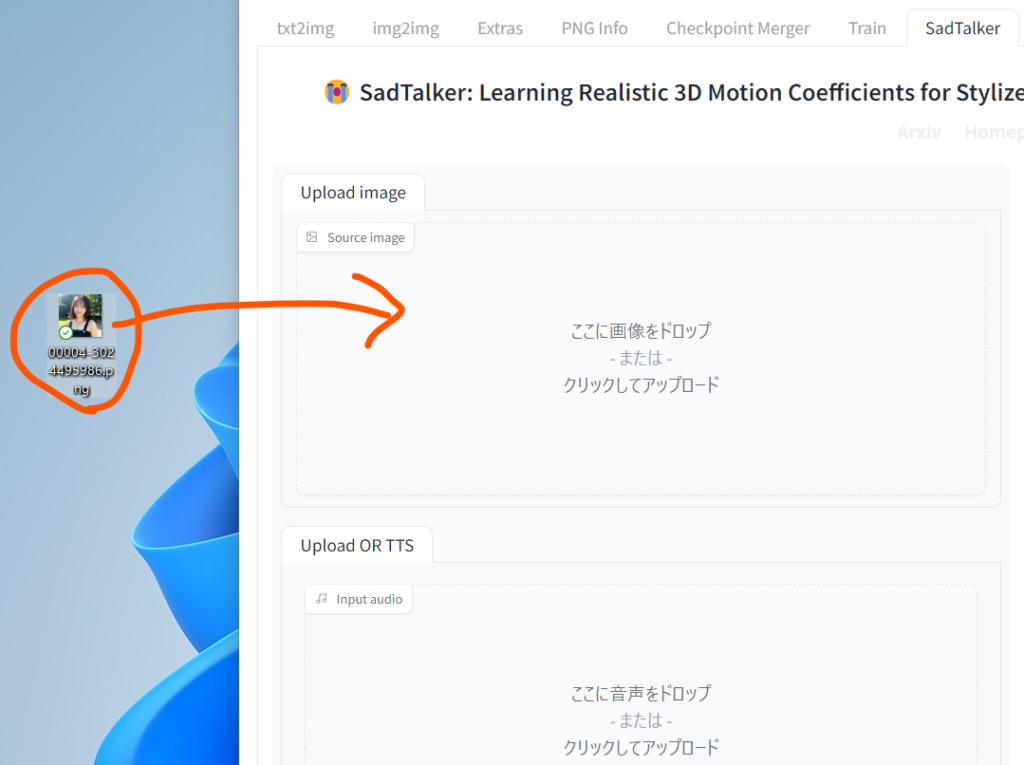
txt2imgで生成した画像でももちろん大丈夫です。
※画像によってはエラーが出て動作しないこともあります。困ったときはいろいろな画像で試してみてください。
例として、冒頭の動画で使っている画像を貼っておきます。

画面の左側下部には音声データをアップロードします。音声はノイズや背景音がないシンプルなものが良いです。
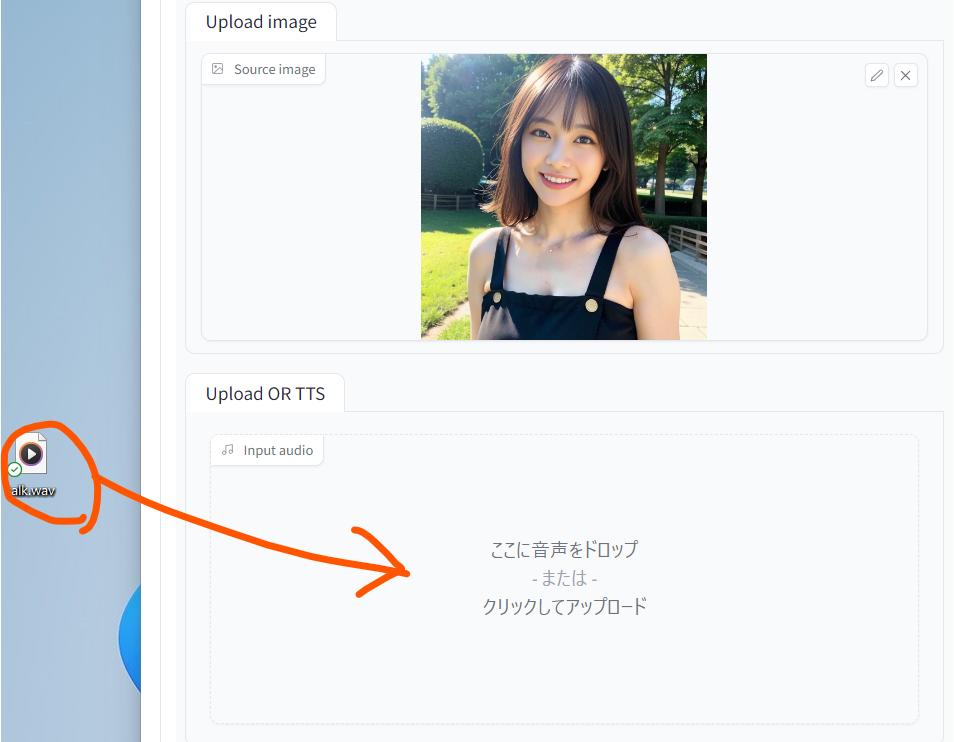
ここではサンプルとして以下のオーディオファイルを用意しました。
これをダウンロードしてドラッグドロップしましょう。
これでしゃべるAI美女を作る準備ができました。
Generateボタンを押してみましょう。
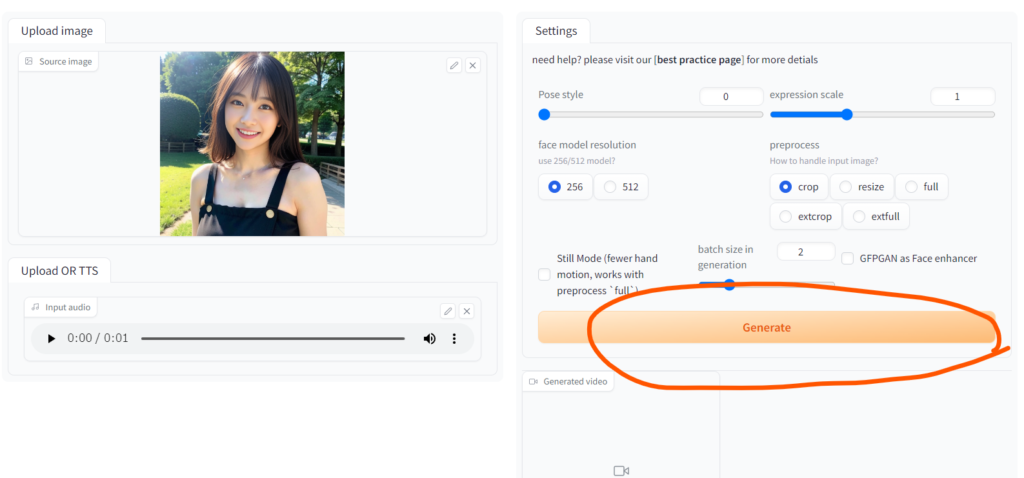
しばらくすると画面右下のGenerated videoに動画が生成されます。
このまま再生してみましょう。
口元が動いて音声と合っていますね。
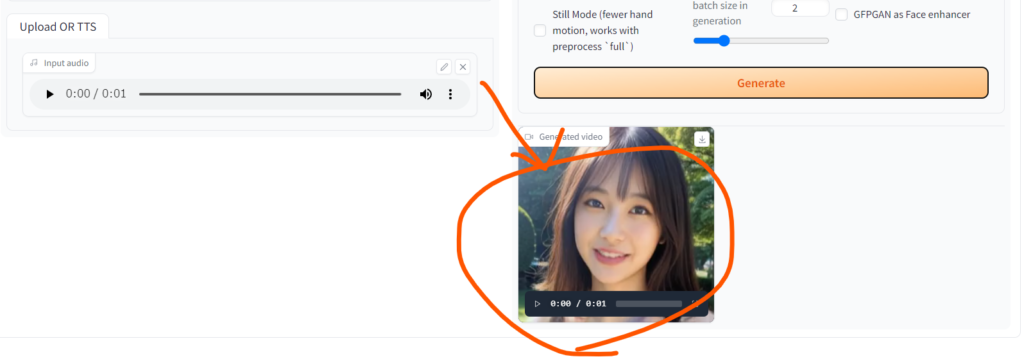
うまくいったら他の画像や音声でも試してみてください。
若干画像が荒かったり、顔だけがくりぬかれた動画になっているところが気になるかと思います。
これらは設定を変えることで改善できます。
ここからはSadTalkerの細かい設定を見ていきましょう。
SadTalkerの設定
続いてSadTalkerの詳しい設定について説明します。
※設定できる内容やUIは更新される場合があります。ここでは2023年6月11日時点のUIで説明します。
SadTalkerの拡張機能のUIでは以下のような設定ができます。
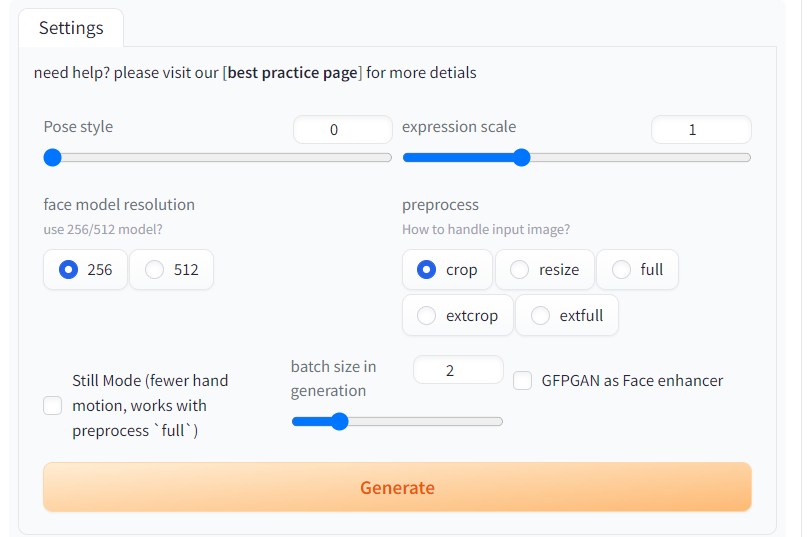
- Pose style
- expression scale
- face model resolution
- preprocess
- Still Mode
- batch size in generation
- GFPGAN as Face enhancer
1. Pose style
Pose styleはポーズのスタイルを46種類から選べる設定です。
以下はPose styleを変えて作成した動画です。
左から順に0, 15, 30, 45に設定しています。
30のとき以外は同じように見えますが、まばたきの回数などが微妙に異なっています。
数字をいろいろ変えて試してみてください。
参考:
pose style [0, 46) #120
Video7: The results of the same driven audio with different styles
test_audio2coeff.py
2. expression scale
expression scaleは表情の動きの大きさの設定です。
数字を大きくするほど動きが大きくなります。
左がexpression scaleが1で、右が2の場合です。
2のほうでは動きが大げさになっているのがわかります。
3. face model resolution
face model resolutionは、顔の解像度を上げる設定です。
256と512の2種類から選べます。
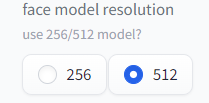
512の方が解像度が高くなります。
左が256で右が512です。たしかに512の方が高解像度に見えますが、動きが崩れてしまっています。
この設定は様子を見ながら選択する必要がありそうです。
4. preprocess
preprocessは動画に変換する前に「画像の大きさ」を調整する設定です。
初期値はcropで顔の部分だけを繰り抜きます。
fullに設定するともとの画像の大きさで変換します。
左がcropで右がfullです。
fullの方が全体が映っていて見ごたえがありますが、首が動くときに肩のあたりで切れてしまいます。
この設定も様子を見ながら設定するといいでしょう。
なお、fullのときに肩のあたりで切れてしまう問題は次のStill Modeの設定で解消できます。
5. Still Mode
Still Modeは手の動きを小さくする設定です。fullモードのときだけ適用されます。

適用すると口だけが動く動画になり、肩のあたりで切れてしまう問題もなくなります。
左がStill Modeオフで右がオンです。
右の方では口だけが動いていて「加工した感」が軽減されています。
長い動画ではStill Modeだと動きが少なすぎて不自然ですが、短い動画ならStill Modeをオンにしていても違和感はなさそうです。
6. batch size in generation
batch size in generationは生成時のバッチサイズの設定です。
初期値のままでよさそうです。
7. GFPGAN as Face enhancer
GFPGAN as Face enhancerは、GFPGANという顔修正モデルを使って顔を修正するモードです。
チェックを入れるとよりきれいな動画になります。

変換に時間がかかってもよければ、使った方がよいです。
左がGFPGANなしで、右がありです。
右の方が圧倒的にきれいになっています。
まとめ
この記事では、Stable Diffusion web UI(AUTOMATIC1111)とSadTalkerの拡張機能を使ってしゃべるAI美女を作る方法を解説しました。
準備が少し大変ですが、一度できればあとは簡単なので根気強く取り組んでみてください。
記事の内容にわからないことがある方は以下のアカウントに気軽にDMしてください!
また、最新の技術の活用方法など役に立つツイートを心がけているので、ぜひフォローしてもらえると嬉しいです!

コメント
こちらためしたのですが
TypeError: save_pil_to_file() got an unexpected keyword argument ‘format’
このようなエラーが出るのですが対処法分かりますでしょうか?
ありがとうございます。エラーの内容を見る限りライブラリのバージョンに不整合があるのだと思います。
以下に全く同じエラーを解決した事例がありました。
https://github.com/OpenTalker/SadTalker/issues/430
↑のページを見た限りでは
requirements.txtの「gradio」の行を「gradio==3.31.0」に変更すると解決しそうです。
試してみてください。