
APIの設計で悩んでいませんか?
よいAPIを設計するためにREST APIを学ぶことはとても有意義です。
RESTの考え方を学べば、柔軟で拡張しやすいAPIを作れるようになります。
この記事では、REST APIについて初心者向けにわかりやすく解説します。
REST APIとは?
REST API(レスト・エーピーアイ)とは「REST(レスト)」に従って作られたAPIのことです。
REST APIを正しく理解するには、まずRESTとAPIを理解する必要があります。
APIとは?
はじめにAPIについて説明します。
APIの意味を既に知っている方は飛ばしてください。
APIとは「Application Programming Interface」の略で、プログラムやシステム同士がやりとりをするための窓口のようなものです。
Interface(インターフェース)とは、日本語では「接点」や「境界面」のことです。
たとえば、人間とコンピュータとの接点をユーザー・インターフェース(UI)と呼ぶことがあります。
パソコンのキーボードや、スマートフォンの画面、回転寿司のタッチパネルなども、人とコンピュータをつなぐユーザー・インターフェースです。
「コンピュータと人間が触れ合う部分」ということですね。これをユーザー・インターフェースといいます。
一方で、今回説明するAPI(アプリケーション・プログラミング・インターフェース)は、プログラムやシステム同士のインターフェースです。
「プログラムとプログラムが触れ合う部分」という意味ですね。
たとえば、Pythonのプログラムを使ってWEBサーバーからデータを取得するとき「WEB API」を使います。
PythonプログラムとWEBサーバーのプログラムをつなぐインターフェースなので、API(アプリケーション・プログラミング・インターフェース)というわけです。
RESTとは?
次にRESTを解説します。
「REST(Representational State Transfer)」とは、HTTPの設計者の1人であるRoy Fieldingが2000年に提唱したAPIの設計の考え方です。
当時、ソフトウェアとネットワークの研究が進む中で、ネットワークへの接続を前提としたソフトウェアの設計指針として考案されました。
それ以前は、単体のコンピュータで動くソフトウェアがほとんどだったため、ソフトウェアの設計だけを考えていればよかったのですが、コンピュータをネットワークに接続することが一般的になってきたため、ネットワークにつながるソフトウェアの設計を考える必要がでてきたんですね。
RESTのルール
一般的に、ソフトウェアを設計する際にはいくつかのルールを決めます。
ルールを決めて守ることで、一貫性のある整った設計ができるというわけです。
RESTには、以下の6つのルールが定められています。
これら6つのルールを守って設計することで、よいAPIを作ることができます。
- クライアント・サーバーの分離
- ステートレス
- キャッシュ可能
- 統一インターフェース
- 階層化システム
- コードオンデマンド
それぞれ詳しく説明します。
1. クライアント・サーバーの分離
「クライアント・サーバーの分離」は「クライアント」と「サーバー」のコンピュータを分離しようという考え方です。
この考え方は「クライアント・サーバーアーキテクチャ」としてよく知られていますね。
RESTは「クライアント・サーバーアーキテクチャ」を前提としています。
「クライアント・サーバーアーキテクチャ」とは「UIを提供するコンピュータ(クライアント)」と「リソース(テキスト情報や画像データなど)を提供するコンピュータ(サーバー)」を分離するアーキテクチャです。
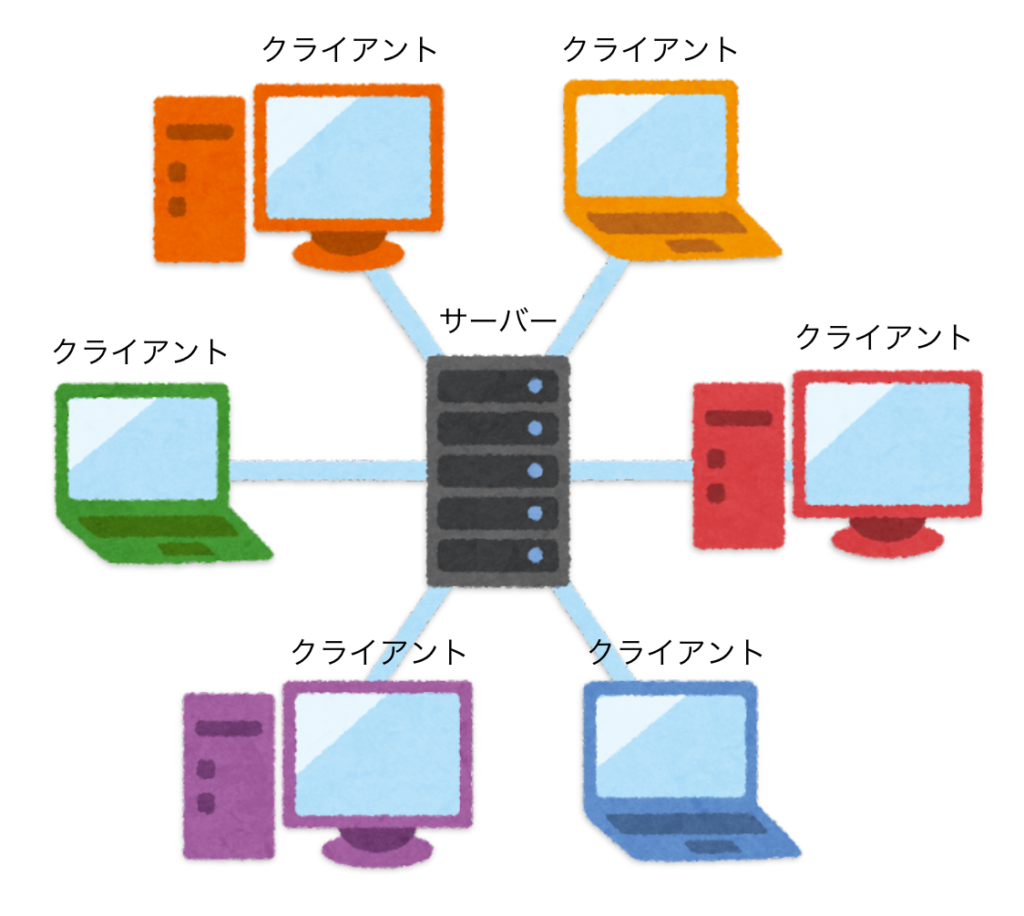
私たちがWEBブラウザを使ってWEBサイトを見るとき、サイトを見ているパソコンやスマートフォンが「クライアント」にあたります。一方で、WEBサイトのデータを返してくるコンピュータが「サーバー」です。
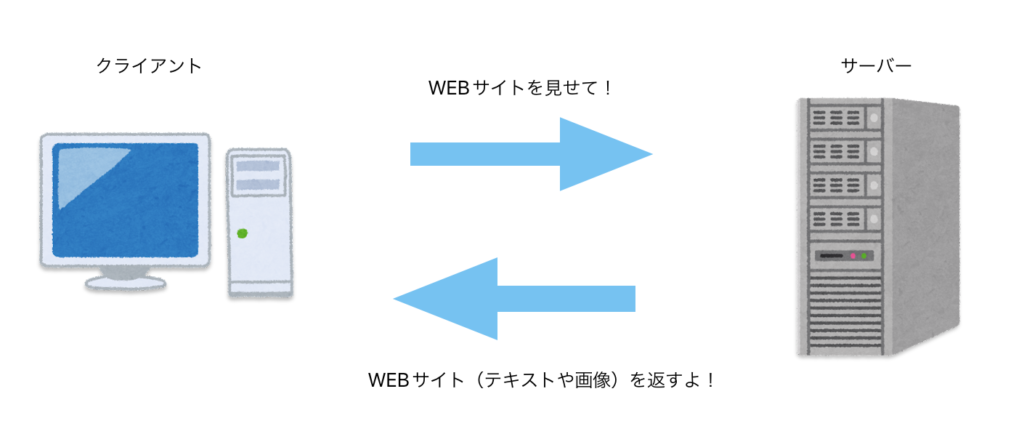
クライアント・サーバーアーキテクチャは、いまやWEB開発では当たり前の構成ですが「クライアント」(UI)と「サーバー」(リソース)の分離は、ネットワークを前提としたソフトウェアの開発において移植性を高めるためにとても効果的です。
RESTに基づく設計では、クライアントとサーバーを分離することが必須の前提になります。
2. ステートレス
ステートレスは「クライアントからサーバーへのリソースの要求には、要求を解釈するために必要な情報をすべて含めなければならない」というルールです。
クライアントからサーバーにリクエストを投げるときにサーバーの状態に依存してはいけません。
「サーバーの状態に依存してはならない」という意味で「Stateless(状態を持たない)」ということです。
これは言いかえれば、リクエストに必要な情報はすべてクライアント側から渡す必要があるということでもあります。
具体例で説明しましょう。
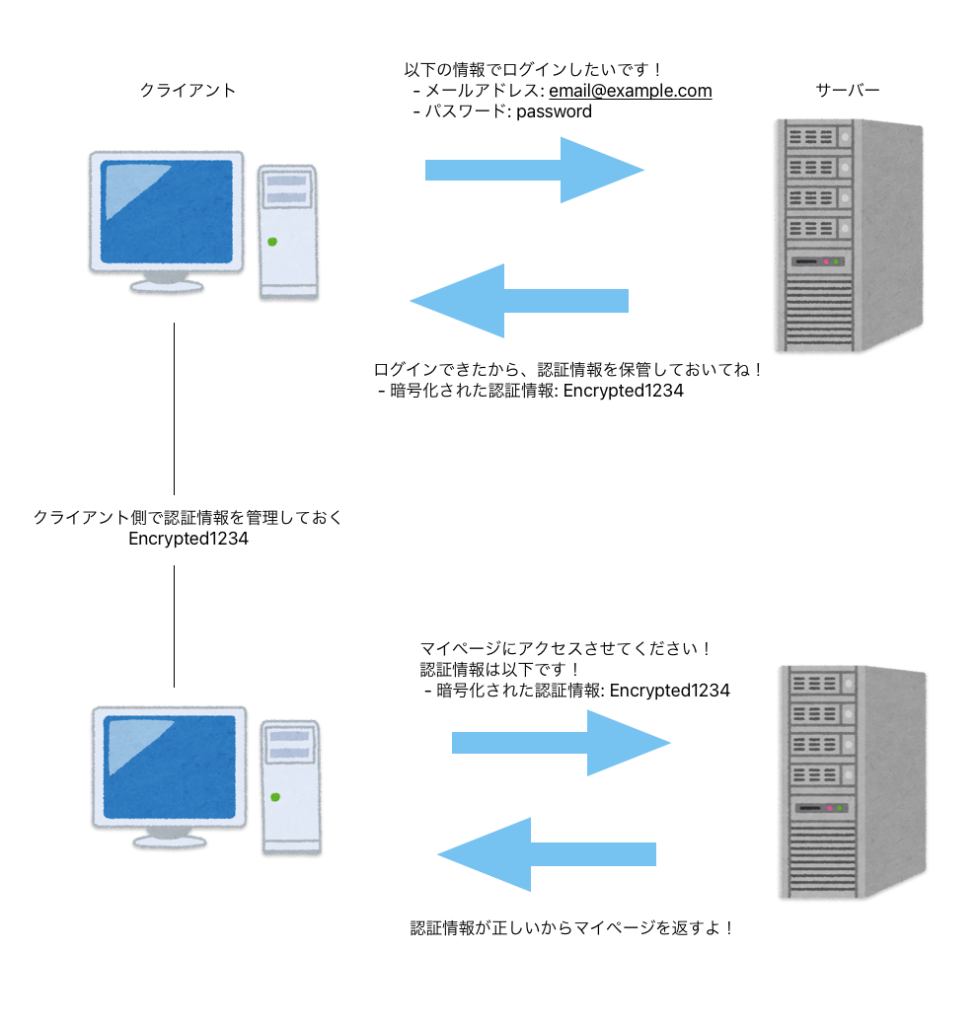
WEBでログイン認証を実装したことがある人ならわかると思いますが、認証情報はふつうクライアント側(ブラウザ側)で管理します。
ユーザーがログインした後、認証情報はWEBブラウザに保存されており、画面の遷移などのタイミングで毎回サーバー側に送信されます。
サーバーはリクエストを受けるたびに、受け取った認証情報を参照して必要な情報を返します。
クライアント側で認証情報を管理していて、サーバー側はログインの状態を管理していません。
これがステートレスであるということです。
ステートレスな通信を守ることで、システムの信頼性や拡張性が増すというメリットがあります。
クライアント・サーバーアーキテクチャでは、ひとつのサーバーに対して、クライアントが複数になります。そのため、サーバー側で状態を管理してしまうと一部の障害が全体に波及します。
クライアント側で状態を管理することによって障害からの回復が簡単になります。
また、サーバー側で状態を管理しないため実装が簡単になるので、システムを拡張させやすくなります。
一方、ステートレスな通信にはデメリットもあります。
リクエストのたびにクライアント側からすべての情報を送信しなければならないため、ネットワークの負荷が大きくなります。サーバー側ではリクエストのたびに同じ処理を繰り返す必要があるため、オーバーヘッドがかかります。
また、サーバー側のリソースに変更があった場合、クライアント側はリクエストを送り直さないとその変更を知ることができません。
そのため、リクエストの回数が増えてネットワークの負荷が大きくなります。
3. キャッシュ可能
キャッシュ可能とは「サーバーはレスポンスに含まれるデータのキャッシュ可否を知らせるべき」というルールです。
キャッシュの可否を明示的に示すか暗黙的に示すかは自由ですが、サーバー側でキャッシュの可否を示します。
キャッシュ可能な場合、クライアントはレスポンスに含まれるデータをキャッシュすることができます。
このルールを守ることによって、通信におけるデータ量を抑え、ネットワークの負荷を下げることができます。
ネットワークの負荷を下げられるメリットがある一方で、キャッシュにはデータの信頼性が損なわれる場合があるというデメリットもあります。
キャッシュされたデータが、サーバーにある最新のデータと大きく異なる場合、システムの不具合の原因になりうるのです。
WEBアプリのフロントエンド開発を経験したことがある人なら、ブラウザのキャッシュをクリアするためにスーパーリロードを試したことがあると思います。
キャッシュをクリアしないと、フロントエンドの変更が反映されず予期しない動作をすることがあります。
これがキャッシュのデメリットです。
とはいえ、現在のHTTPでは必要に応じてクライアントにキャッシュをクリアさせる方法があるため、適切に対策すれば問題ありません。
ネットワークの負荷を下げ、通信を効率化できるメリットのほうが大きいでしょう。
4. 統一インターフェース
RESTの4つ目のルールは統一インターフェースです。
統一インターフェースは「システムへのアクセスのインターフェースを統一するべき」というルールです。
インターフェースとは、システムとやりとりをする窓口のことでした。
RESTではどんなサービスを提供するかによらず、インターフェースを統一します。
これは言いかえれば「どんなリソースを要求するときでも同じ形式で要求できる」ということです。
これによって、システム全体の設計がシンプルになります。
このルールはHTTPの設計に反映されています。
たとえば「URIでリソースを一意に定めてアクセスできる」「JSON, XMLなど表現型を通して操作できる」「GET, POST, PUT, DELETEなどのメソッドを通してリソースへの操作を記述できる」などがあります。
HTTPではこれらの統一されたインターフェースに従うことでシンプルな設計を実現できています。
WEB APIを設計するときは、HTTPの仕様をよく理解して適切に利用すれば、統一インターフェースのルールを達成できます。
5. 階層化システム(レイヤードシステム)
RESTの5つ目のルールは階層化システムです。
階層化システムとは、システムの構成要素(コンポーネント)を関連する要素ごとに階層に分離するアーキテクチャのことをいいます。
階層化システムの発想は、システムを設計したことがある人なら、レイヤードアーキテクチャという名前でよく知っていると思います。
RESTにおいてもシステムを階層に分離して設計することがひとつのルールとなっています。
複数のコンポーネントを責務によって階層化し、お互いに関係のないコンポーネントを参照できないように制限することで、システム全体の構造をシンプルに保ち、複雑化を防ぐことができます。
RESTではクライアントとサーバーの分離が前提になっているため、それだけで2層のアーキテクチャになります。
これらに加えてプロキシやゲートウェイの層を作ることで、より階層化されたシステムになります。
具体的にどのように階層化するかは設計者に委ねられるところですが、システムが大きい場合は「負荷分散」「認証・認可」「キャッシュ」「セキュリティチェック」などの階層を増やすことが考えられます。
このような階層化によって保守しやすいシステムを実現できます。
ただし、階層化にもデメリットがあります。
複数のコンポーネントを経由してデータを処理するため、処理のオーバーヘッドと遅延が増えてしまいます。
階層化の設計は難しいところですが、システムをシンプルに構造化して保守しやすくするメリットと、それによって増加する処理のオーバーヘッドや遅延のリスクを天秤にかけて、適切なレベルでの階層化を考える必要があります。
6. コードオンデマンド
コードオンデマンドとは、クライアント側で実行できるスクリプトをサーバーから返すというルールです。
クライアント側で実行できるスクリプトを用意することで、クライアントの実装コストを下げることができます。
現代のWEBアプリケーションでは、クライアント(ブラウザ)で実行できるJavaScriptを返すのが当たり前になっていますね。
これがコードオンデマンドです。
ただし、このルールはRESTのルールの中で唯一、任意のものです。
クライアントで実行可能なスクリプトを返すかどうかは設計者が自由に決められます。
仮に実行可能なスクリプトを返さない設計にしたとしてもRESTであるといえます。
「RESTとは?」のまとめ
以上のようにRESTでは、具体的な6つのルールが定められています。
これらのルールを守って設計することでREST APIを作ることができます。
「REST」と「REST API」と「RESTful API 」の違い
RESTについて学ぶと「REST API」と「RESTful API」という用語に遭遇します。
ここで、これらの用語の違いを明確にしましょう。
まずRESTは、ここまでに紹介した「Roy Fielding氏が提唱した設計原則」のことです。
REST自体は「設計の考え方」であって具体的な実装ではありません。
一方「REST API」と「RESTful API」は、どちらもRESTに従って実装されたAPIのことを指します。
「REST API」と「RESTful API」の違いは「どれくらい厳密にRESTを守っているか」にあります。
およそRESTに従って実装したAPIを「REST API」と呼ぶのに対し、RESTに完全に従ったAPIを「RESTful API」と呼びます。
- RESTは、Roy Fielding氏が提唱した設計原則のこと
- REST APIは、RESTにそこそこ従ったAPI
- RESTful APIは、RESTに完全に従ったAPI
これらの用語の使い分けにこだわる必要はありませんが、知っておくと良いでしょう。
RESTに厳密に従うべきか?
さて、APIの設計において、私たちソフトウェアの設計者はRESTのルールを完璧に守らなければいけないのでしょうか?
その判断は各々にゆだねられていますが、常にRESTに従わなければいけないわけではありません。
RESTはあくまでも設計の考え方ですから、守らなくてもAPIは動作します。
実稼働するシステムのAPIでもRESTを完全に遵守していないものはたくさんあります。
とはいえ、RESTで定義された制約に厳密に従うことによって、ある程度はAPIを作れることも確かです。
特に、あなたがAPI設計を勉強中なら、RESTに従ってAPIを作ってみることはとても有意義です。
RESTには「階層化」や「ステートレス」「統一インターフェース」など優れた設計のエッセンスが詰まっています。
RESTをしっかり理解することで設計のスキルも向上します。
ぜひRESTを学んで実践に役立てましょう。
まとめ
この記事では、REST APIについて解説しました。
- RESTとはネットワークへの接続を前提としたソフトウェアの設計の考え方
- RESTには6つのルールが定められいる
- それらのルールを守ることで優れたAPIを設計できる
- REST APIとはRESTに従って作られたAPIのこと
- RESTful APIとはRESTのルールに完全に従ったAPIのこと
- RESTに完全に従わなくてもAPIは設計できるが、従うことでよりよいAPIを実現できる

