
Common Crawl(コモン・クロール)はインターネット上のWEBサイトを定期的にクローリングし、そのアーカイブを公開しているプロジェクトです。
クローリングされたWEBサイトのデータは無料で公開されており、巨大なデータセットとして使用できます。
この記事ではCommon CrawlにアーカイブされたWEBサイトのデータを取得し、その内容を解析する手順を説明します。
1. アーカイブを探す
Common Crawlにアクセスしてデータを探します。
データはGet Startedのページから一覧を見ることができます。
今回は2023年の3月、4月のデータを見てみましょう。
一覧からMarch/April 2023のページにアクセスします。
以下のようにファイルリストが並んでいます。
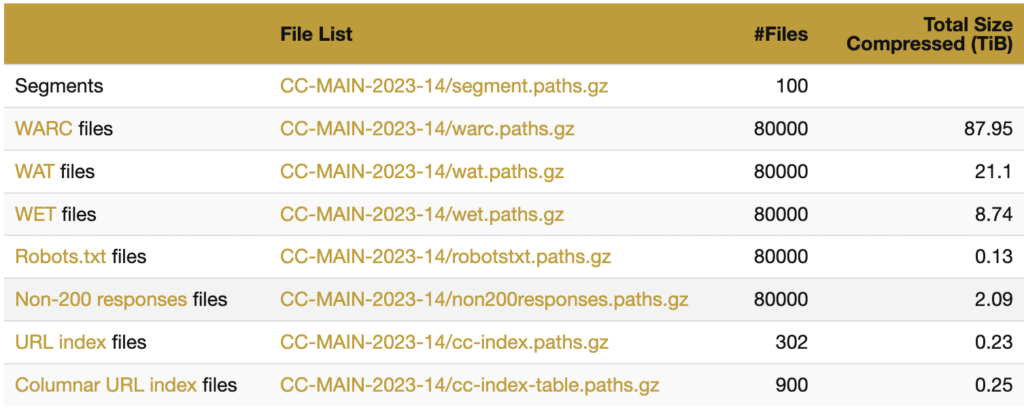
ファイルリストの「WARC Files」にある CC-MAIN-2023-14/warc.paths.gz をクリックするとWARCファイルへのパスの一覧を取得できます。
WARCは、WEBサイトをアーカイブするためのフォーマットで、Web Archiving(ウェブアーカイブ)からきています。
2. アーカイブファイルへのパスをダウンロードする
warc.paths.gz という圧縮されたファイルがダウンロードされます。
これをgzipコマンドで展開します。
gzip -d warc.paths.gz展開すると、以下のようにパスが一覧になって入っています。
crawl-data/CC-MAIN-2023-14/segments/1679296943471.24/warc/CC-MAIN-20230320083513-20230320113513-00000.warc.gz
crawl-data/CC-MAIN-2023-14/segments/1679296943471.24/warc/CC-MAIN-20230320083513-20230320113513-00001.warc.gz
crawl-data/CC-MAIN-2023-14/segments/1679296943471.24/warc/CC-MAIN-20230320083513-20230320113513-00002.warc.gz
...これがCommon CrawlによってクロールされたWEBサイトのアーカイブがあるパスです。
これらを使ってアーカイブされたデータの本体にアクセスできます。
3. アーカイブファイル本体をダウンロードする
上記で取得したパスの先頭に https://data.commoncrawl.org/ をつけるとデータの所在を示すURLになります。
ここにアクセスすればアーカイブされたファイルを圧縮したデータがダウンロードできます。
https://data.commoncrawl.org/crawl-data/CC-MAIN-2023-14/segments/1679296943471.24/warc/CC-MAIN-20230320083513-20230320113513-00000.warc.gz圧縮された状態で1.2GBくらいです。
これを gzipコマンドで展開します。
gzip -d CC-MAIN-20230320083513-20230320113513-00000.warc.gz展開されたファイルは数GBになります。
4. WARCファイルを開く
展開されたファイルをテキストエディタなどで開けばアーカイブデータをそのまま確認できますが、ファイルサイズが大きいため直接開くのは危険です。
そこで、ここではPythonで分割しながら開くことにします。
warcファイルを見るために、Pythonのモジュールである「warcio」をインストールします。

pip経由でインストールできます。
pip install warcio以下のようにしてwarcioでwarcファイルを読み込むことができます。
ArchiveIteratorを使うことでメモリを圧迫せず、ファイルを分割しながら読むことができます。
ここでは record.rec_headers.get_header('WARC-Target-URI') でURIを表示しています。
from warcio.archiveiterator import ArchiveIterator
with open('ファイル名.warc', 'rb') as stream:
for record in ArchiveIterator(stream):
if record.rec_type == 'response':
print(record.rec_headers.get_header('WARC-Target-URI'))データの中身を見るには以下のようにします。
record.raw_streamで生のデータを読むことができます。
from warcio.archiveiterator import ArchiveIterator
with open('ファイル名.warc', 'rb') as stream:
for record in ArchiveIterator(stream):
print(record.raw_stream.read())5. おまけ:特定のキーワードを含むサイトのコンテンツを読む
上記ではすべてのデータが標準出力されます。
大規模データのためそのまま眺めるのは大変です。
読み込んだデータを特定のキーワードで検索し、キーワードを含むコンテンツだけを取得しましょう。
例として、以下のようなクラスを作成しました。
from warcio.archiveiterator import ArchiveIterator
class WebArchive:
def __init__(self, filepath):
self._filepath = filepath
def _is_utf8(self, bytes_obj):
try:
bytes_obj.decode('utf-8')
return True
except UnicodeDecodeError:
return False
def serach(self, keyword):
result = []
with open(self._filepath, 'rb') as f:
for record in ArchiveIterator(f):
if record.rec_type == 'response':
content = record.content_stream().read()
if (self._is_utf8(content)):
content_str = content.decode('utf-8')
if keyword in content_str:
result.append(record.rec_headers.get_header('WARC-Target-URI'))
return result
def read_content(self, uri):
with open(self._filepath, 'rb') as f:
for record in ArchiveIterator(f):
if record.rec_type == 'response' and record.rec_headers.get_header('WARC-Target-URI') == uri:
result = record.content_stream().read()
if (self._is_utf8(result)):
result = result.decode('utf-8')
return resultこのWebArchiveクラスを用いて、指定したキーワードを含むコンテンツを抽出できます。
ここでは抽出したコンテンツをBeautifulSoupで解析し、テキストデータを取り出します。
BeautifulSoupもpipでインストールできます。
pip install beautifulsoup4以下のようにして該当するキーワードを含むコンテンツを標準出力できます。
from bs4 import BeautifulSoup
file_path = "ファイルパス.warc"
web_archive = WebArchive(file_path)
for url in web_archive.serach("キーワード"):
content = web_archive.read_content(url)
soup = BeautifulSoup(content, 'html.parser')
print(soup.get_text().replace("\n", ""))まとめ
この記事ではCommon CrawlからWEBのアーカイブを取得して、過去のWEBサイトのデータを読む方法を解説しました。
記事の内容にわからないことがある方は以下のアカウントに気軽にDMしてください!
また、最新の技術の活用方法など役に立つツイートを心がけているので、ぜひフォローしてもらえると嬉しいです!

